
こんにちは ハタ です。
Mirrativ では 2020年頃から サーバサイドの技術をPerlからGoへのシステム移行 を行っており、2024年現在でもサグラダファミリアのように移行作業は継続しています
PerlとGoという2つの環境を同時に運用していますが、
基本的には 新機能は Go で実装 し、 Perlでは積極的に新規実装を行わない というスタイルで進めていました
しかし、既存の機能の一部に手を加えたいとなった場合、まだまだ Perl の実装に手を加えることが一定あり、Perl から Go の機能を呼び出したいというニーズが出てきました
(配信やギフトといったビジネスの根幹を支えるレガシーな実装においては顕著)
そこで PerlXS を利用することで Perl から Go を直接呼び出せるようにできないかと考え検証を進めることにしました
Goの -buildmode=c-shared で共有ライブラリ化し、XS でバインディングを書くことで比較的簡単かつ高パフォーマンスも実現できそうです
また同時期にmemcachedにおけるキーによるクライアント側分散処理を開発していましたが、 Perlの Cache::Memcached::Fast の Ketama consistent hashing と Goの bradfitz/gomemcache の Selector で参照するサーバが異なる問題を解消するために、Go実装の CustomSelector に実装を寄せようと XS 化を作成していたのもあり、Goで作成した機能を Perlから呼び出せるように出来るとさまざまな機能を統合できメンテナンス性が向上できそうと考えました *1
PerlXSによるGo連携には、いろいろ試行錯誤したため紹介していきたいと思います
背景と目的
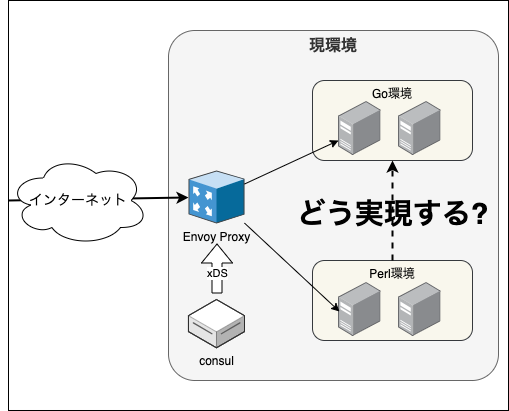
上記に述べた通りミラティブでは、サーバサイドの技術を Perl から Go へのシステム移行を行っています
これまで PerlとGoの両環境へは Envoy xDSを用いてトラフィックを振り分ける平行運用 を行ってきています
このような環境の中で Perl から Go の機能を呼び出しを実現するには RPC(Remote Procedure Call)のような通信、つまり内部通信を行って機能を呼び出すのが一般的に行われる手法かなと思います
しかし、内部通信を行えるようにするとアプリケーション間の結合度が上がってしまい保守性に課題が生じます
また、可用性を高めるために内部ロードバランサーの導入など必要なコンポーネントが増えてしまいそうです *2
そこで、Goのアプリケーションを共有ライブラリ化してしまい、PerlXSを用いて Perl から 直接 Go の機能を呼び出せるようにすることで、複雑性を高めることなく Go の機能を呼び出すようにしようと考えました
Goをシングルバイナリにするのと同じように共有ライブラリ(*.soファイル)にしてしまえば、既存のデプロイフローを大きく変える必要もなく内部ロードバランサーなどのコンポーネントが増えることもなくなりそうです
何よりネットワークの通信等が減るため高パフォーマンスで処理することが期待できます
パフォーマンス面ではなく開発体験としても 先述したとおり Perl XS を通じて 今まで仕方なく Perl で作らざるを得なかった機能を Go で実装できるようになれば、Perl から Go の移行を加速できる可能性がありそうです
特に古くから存在する Perl のコードは、複雑で大きいのですが関数のように呼び出しができれば、少しずつ Go に置き換えやすくなりそうです
PerlXS と Goの共有ライブラリ
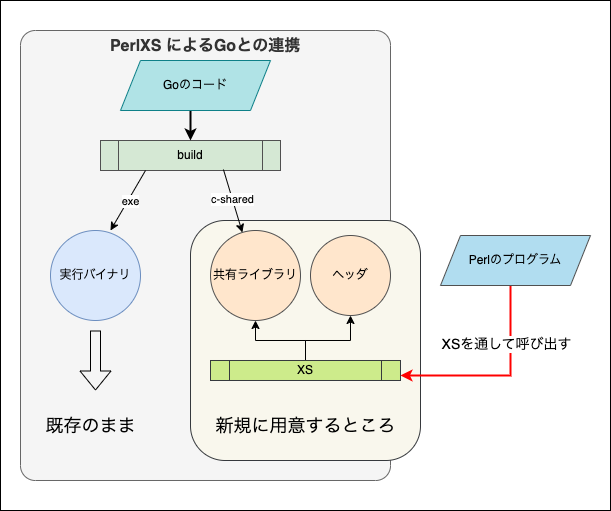
まず先に Go の共有ライブラリを XS で呼び出せるようにするところを紹介させてください
PerlXS は、XSという言語で記述された C 関数の呼び出しの定義を書くことで Perl からリンクできるようにする仕組みです
Go からは CGO を用いた //export コメントを使うことで C 関数として外部から呼び出せれるように定義できます
まずは Go のコードです
package main /* #include <stdlib.h> #include <stdint.h> #include <string.h> typedef struct myxs_context_t { int32_t counter; void *buf; } myxs_context_t; */ import "C" import ( "bytes" "unsafe" ) //export create_myxs_context func create_myxs_context(initialVal C.int) (*C.myxs_context_t, C.int) { s := C.size_t(C.sizeof_struct_myxs_context_t) p := C.malloc(s) if p == nil { return nil, C.int(-1) } C.memset(p, 0, s) ctx := (*C.myxs_context_t)(p) ctx.counter = C.int32_t(initialVal) ctx.buf = unsafe.Pointer(bytes.NewBuffer(nil)) return ctx, C.int(0) } //export free_myxs_context func free_myxs_context(ctx *C.myxs_context_t) { C.free(unsafe.Pointer(ctx)) } //export increment_counter func increment_counter(ctx *C.myxs_context_t) { ctx.counter += 1 } //export get_counter func get_counter(ctx *C.myxs_context_t) C.int32_t { return C.int32_t(ctx.counter) } //export add_buffer func add_buffer(ctx *C.myxs_context_t, buf *C.char, size C.int) { b := (*bytes.Buffer)(ctx.buf) b.WriteString(C.GoStringN(buf, size)) } //export get_buffer func get_buffer(ctx *C.myxs_context_t) (*C.char, C.int) { b := (*bytes.Buffer)(ctx.buf) return C.CString(b.String()), C.int(b.Len()) } func main() {}
単純なインクリメントを行うものと文字列を保存するだけのシンプルな機能です
これを go build --buildmode=c-shared でビルドすることで 共有ライブラリとヘッダファイルが生成されます
$ mkdir build $ cd build $ go build --buildmode=c-shared -o libmyxs.so ../main.go $ ls libmyxs.h libmyxs.so
次に生成された libmyxs.so と libmyxs.h を XS を使ってPerlから呼び出せれるように定義します
#define PERL_NO_GET_CONTEXT #include "EXTERN.h" #include "perl.h" #include "XSUB.h" #include "ppport.h" #include "libmyxs.h" MODULE = MyXS PACKAGE = MyXS void _create(initial_val) int initial_val; PROTOTYPE: $ PPCODE: { struct create_myxs_context_return ret = create_myxs_context(initial_val); myxs_context_t *ctx = ret.r0; int ok = ret.r1; if(0 != ok) { XPUSHs(sv_2mortal(&PL_sv_undef)); XPUSHs(sv_2mortal(newSViv(ok))); XSRETURN(2); return; } SV* sv_ctx = sv_2mortal(newSViv(PTR2IV(ctx))); XPUSHs(sv_2mortal(newRV_inc(sv_ctx))); XPUSHs(sv_2mortal(newSViv(ok))); XSRETURN(2); return; } void _destroy(ctx) myxs_context_t *ctx; PROTOTYPE: $ CODE: { free_myxs_context(ctx); } void _incr_counter(ctx) myxs_context_t *ctx; PROTOTYPE: $ CODE: { increment_counter(ctx); } void _get_counter(ctx) myxs_context_t *ctx; PROTOTYPE: $ PPCODE: { int val = get_counter(ctx); XPUSHs(sv_2mortal(newSViv(val))); XSRETURN(1); } void _add_buffer(ctx, str) myxs_context_t *ctx; SV *str; PROTOTYPE: $$ PPCODE: { const char* value; STRLEN value_len; SvGETMAGIC(str); if(SvOK(str)) { value = SvPV(str, value_len); } else { croak("failed to call _add_buffer: str"); } add_buffer(ctx, value, value_len); } void _get_buffer(ctx) myxs_context_t *ctx; PROTOTYPE: $ PPCODE: { struct get_buffer_return ret = get_buffer(ctx); size_t buf_len = ret.r1 * sizeof(char); char* buf = malloc(buf_len); memcpy(buf, ret.r0, buf_len); free(ret.r0); EXTEND(SP,1); SV* sv = sv_2mortal(newSVpv(buf, buf_len)); XPUSHs(sv); XSRETURN(1); Safefree(buf); }
少しみなれない書き方になっていますが、基本的には C でライブラリを呼び出す方法と同じです
なお、Goから返される多値は下記のように struct {func}_return で定義されています *3
struct get_buffer_return { char* r0; int r1; }; extern struct get_buffer_return get_buffer(myxs_context_t* ctx);
さてXSの定義が出来たら、あとはPerlから呼び出せれるようにパッケージを用意します
これはPerlで記述します
package MyXS; use 5.030000; use strict; use warnings; our $VERSION = '0.01'; our $LIB = 'libmyxs.so'; BEGIN: { use DynaLoader; use File::Basename; my (undef, $dir) = fileparse(__FILE__); my $pathes = [ "${dir}/../../${LIB}", # /path/to/libxs.so "/usr/local/lib/${LIB}", "/usr/lib/${LIB}", ]; my $not_founds = []; my $load_file = undef; for my $path (@$pathes) { my $lib = DynaLoader::dl_load_file($path, 1); if(defined($lib)) { $load_file = $lib; last; } push(@$not_founds, $path) } die "couldnt load library " . join(" ", @$not_founds) unless defined($load_file); } sub new { my ($class, $initial_value) = @_; my ($ctx, $ok) = _create($initial_value); if($ok != 0) { die "failed to create MyXS object: $ok"; } return bless(+{ ctx => $ctx, }, $class); } sub DESTROY { my $self = shift; _destroy($self->{ctx}); } sub incre_counter { my $self = shift; _incr_counter($self->{ctx}); } sub get_counter { my $self = shift; my $value = _get_counter($self->{ctx}); return $value; } sub add_buffer { my ($self, $str) = @_; _add_buffer($self->{ctx}, $str); } sub get_buffer { my ($self, $str) = @_; return _get_buffer($self->{ctx}); } require XSLoader; XSLoader::load(__PACKAGE__, $VERSION); 1;
ここまで出来れば、あとは呼び出すだけです
use strict; use warnings; use MyXS; my $xs = MyXS->new(10); for (1..10) { $xs->incre_counter(); } print($xs->get_counter()); # => 20 $xs->add_buffer("hello"); $xs->add_buffer("world"); print($xs->get_buffer()); # => "helloworld"
これでGoの関数をPerlから呼び出せるようになりました
XSを使うことで あたかも Perl であるかのように使えて自然です
XSによる呼び出しパフォーマンス
念の為簡単なパフォーマンスもチェックしてみます
1つは Perlの Digest::MD5 と Goの crypto/md5 の比較です
Digest::MD5はXS化されている ため、XS と CGO によるオーバーヘッドによって差が出るのかが分かるかもしれません
2つめは アッカーマン関数 です、単純に計算量が多い処理を用意し、CGO のメリットがあるのかがわかるかもしれません
3つめは 1 だけを出力する空の関数です、オーバヘッドがどれくらい存在するのかを確認できるはずです
先程のGoに次のように追加し
//export md5_hex func md5_hex(buf *C.char, size C.int) (*C.char, C.int) { s := C.GoStringN(buf, size) b := unsafe.Slice(unsafe.StringData(s), len(s)) h := md5.Sum(b) hex := hex.EncodeToString(h[:]) return C.CString(hex), C.int(len(hex)) } //export ackermann func ackermann(m, n C.int) C.int { if m == 0 { return n + 1 } if n == 0 { return ackermann(m-1, 1) } return ackermann(m-1, ackermann(m, n-1)) } //export one func one() C.int { return C.int(1) }
Go単体で呼び出した場合のベンチマーク結果は以下の通りです
なお結果の誤差を減らすため、ackermann では (m=3, n=4) で、 md5 の計算では固定の文字列 hoge を繰り返し計算させています
$ go test -bench=. -benchtime=10s -v ./ goos: linux goarch: amd64 pkg: example.com cpu: Intel(R) Xeon(R) W-11955M CPU @ 2.60GHz Benchmark Benchmark/one Benchmark/one-16 1000000000 0.2204 ns/op Benchmark/ack3,4 Benchmark/ack3,4-16 381193 31132 ns/op Benchmark/md5 Benchmark/md5-16 90010182 128.3 ns/op PASS
続いて Perl では次のようにしました
use strict; use Benchmark qw/timethese/; use Digest::MD5; use MyXS; no warnings 'recursion'; sub ack { my ($m, $n) = @_; return $n + 1 if $m == 0; return ack($m - 1, 1) if $n == 0; return ack($m - 1, ack($m, $n - 1)); }; timethese(-10, { md5_perl => sub { Digest::MD5::md5_hex("hoge");; }, md5_xsgo => sub { MyXS::md5("hoge"); }, ack_perl => sub { ack(3, 4); }, ack_xsgo => sub { MyXS::ack(3, 4); }, one_xsgo => sub { MyXS::one(); } });
これの結果は以下の通りです
Benchmark: running ack_perl, ack_xsgo, md5_perl, md5_xsgo, one_xsgo for at least 10 CPU seconds... ack_perl: 10 wallclock secs (10.37 usr + 0.00 sys = 10.37 CPU) @ 883.61/s (n=9163) ack_xsgo: 10 wallclock secs (10.51 usr + 0.02 sys = 10.53 CPU) @ 32786.99/s (n=345247) md5_perl: 10 wallclock secs (10.50 usr + 0.00 sys = 10.50 CPU) @ 5938536.86/s (n=62354637) md5_xsgo: 11 wallclock secs (10.24 usr + 0.33 sys = 10.57 CPU) @ 2022398.11/s (n=21376748) one_xsgo: 10 wallclock secs (10.22 usr + 0.04 sys = 10.26 CPU) @ 8025350.39/s (n=82340095)
それぞれまとめると
軽量の関数呼び出し
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接one() | 1000000000 | 1.0000 (100%) |
| XSでのone() | 82340095 | 0.0823 (8.23%) |
C.int(1) を返すだけの関数ですが、Goで直接呼び出すものより 8.23% の速度しかでないようです
one_xsgo の回数と時間より 1回あたりの呼び出し速度は 8025350.39/s = 124.60ns/call
軽量すぎる関数の呼び出しは XS 経由の呼び出しでのオーバヘッドが大きいようです
アッカーマン関数の比較
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接ack(3,4) | 381193 | 1.0000 (100%) |
| Perlのack(3,4) | 9163 | 0.0240 (2.40%) |
| XSでのack(3,4) | 345247 | 0.9057 (90.57%) |
Perlでアッカーマンを計算することは無いと思いますが、関数の呼び出しが多かったり計算量が多い場合は Go 実装のほうが速いようです
こちらもGo直接とXSを経由するものでオーバヘッドは感じられますが、Perlで巨大な計算をする場面では有利のようです
MD5関数の比較
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接md5 | 90010182 | 1.0000 (100%) |
| Digest::MD5 | 62354637 | 0.6927 (69.27%) |
| XSでのmd5 | 21376748 | 0.2374 (23.74%) |
こちらは XS上で実装されているMD5 と XS -> CGO で呼び出された場合の比較になると思います *4
そのため CGO でのオーバヘッドになると思いますが、直接XSにロジックを書いている場合には負けるようです
とはいえ、この関数自体は 2022398.11/s = 494.46ns/call となっていて、とてつもなく遅いというわけではありません
2つ前のbenchmarkより、軽量の関数呼び出しで 約120ns
Goのベンチマークより、Go上で直接呼び出すと 約128ns
これらを合わせると 約250ns で、このXSの呼び出しが 約500ns なので、差分が XS 実行にかかる時間のようです
簡単なベンチマークからわかること
XS -> CGOでオーバヘッドがあるため、軽量の関数呼び出しは向いていない- Perl上で大量の計算を行っている場面では、XS 経由の呼び出しにおいても有利
- XSに最適化されているものがあれば、それを使うほうが良い
といったところでしょうか
マイクロなベンチマークなので、 XS -> CGO がそこまでパフォーマンスを振るわないように見えますが、それでも約 900ns 以上 Perl で処理をする場合では XS -> CGO に置き換えるメリットがありそうです *5
このような実装を行えば、軽微ながらパフォーマンスに影響はあるものの、 XS から Go の関数を呼び出せれるのが分かったため
あとは Go の実装を //export で公開していきエントリポイントを作っていくだけ、、の状態なのですが
ここから色々と紆余曲折を経ることになったため、紹介させてください
PerlとGoのプロセスモデルの違い
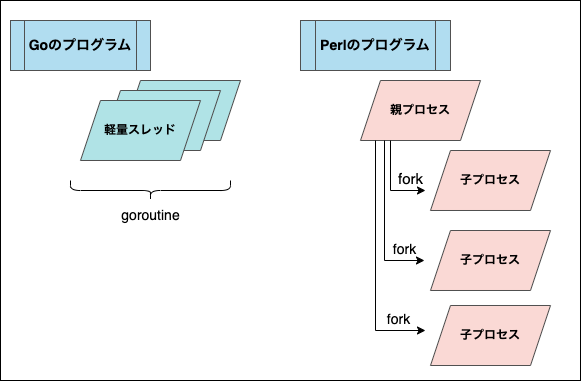
PerlとGoのプロセスモデルの違いというよりも、Goのプロセスモデルと Parallel::Prefork を使った Perl のアプリケーションの違いになるのですが
Mirrativ の Perl Webアプリケーションは Starlet + Server::Starter を使用していて、 Parallel::Prefork によって fork された Prefork 型のプロセスモデルで実行しています
対して Go は goroutine の軽量スレッドによるマルチスレッドモデルです
これら2つのプロセスモデルの違いによって、上手く XS を通じて CGO の連携が行えないパターンがありました
forkとgoroutine
いったん Perl から離れて C のコードで fork(2) を呼び出して、親プロセスと子プロセスで Go の処理を呼び出してみます
使用するのは先程作成した libmyxs.go です
#include <stdio.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> #include "libmyxs.h" void main(int argc, char *argv[]) { struct create_myxs_context_return ret = create_myxs_context(10); if(ret.r1 != 0) { printf("failed to create_myxs_context"); exit(1); } myxs_context_t *ctx = ret.r0; int status; pid_t pid = fork(); if(pid == -1) { printf("failed to fork"); exit(1); } if(pid == 0) { printf("run child\n"); for(int i = 0; i < 5; i += 1){ increment_counter(ctx); } printf("child = %d\n", get_counter(ctx)); exit(0); } printf("run parent\n"); for(int i = 0; i < 10; i += 1){ increment_counter(ctx); } printf("parent = %d\n", get_counter(ctx)); printf("wait_child\n"); for(int i = 0; i < 10; i += 1) { if((pid = waitpid(pid, &status, WNOHANG)) == -1) { printf("failed to waitpid"); exit(1); } if(pid == 0) { printf("child still running\n"); sleep(1); continue; } if(WIFEXITED(status)) { printf("child exit status=%d\n", WEXITSTATUS(status)); exit(0); } } printf("child did not exit successfully\n"); exit(0); }
これを実行すると
$ gcc -g -I. -L. ./main.c -lmyxs && ./a.out run parent run child parent = 20 wait_child child still running child = 15 child status=0
ちゃんと親プロセスで作成した myxs_context_t* も使えており、問題なく処理が進んでいるように見えます
また child = 15 となっていることから CoW にもなっていて、親と子で値が共有されないことも確認できます
では goroutine を使って見るとどうでしょうか
increment_counter を少し変え
//export increment_counter func increment_counter(ctx *C.myxs_context_t) { wait := make(chan struct{}) go func() { ctx.counter += 1 wait <- struct{}{} }() <-wait }
のようにしてみて、再度ビルドし実行します
$ gcc -g -I. -L. ./main.c -lmyxs && ./a.out run parent run child parent = 20 wait_child child still running child still running child still running child still running child still running child still running child still running child still running child still running child still running child did not exit successfully
親プロセスでは問題なく処理が進みまずが、 子プロセスでは goroutine の処理が進むことなく、ハングアップしているようです
GDB を使った追いかけ
では実際にどこで止まっているのでしょうか
go tool cgo main.go を使って事前に生成されるファイル _obj を生成しつつ GDB で少しずつ追いかけます *6
まずは 親プロセス
$ gdb ./a.out -d _obj -d $(go env GOROOT) > set follow-fork-mode parent > set detach-on-fork off > b _cgo_wait_runtime_init_done > run
n を繰り返していくと次の処理を抜けていることがわかります
(gdb) n
...
increment_counter (ctx=0x5555555593d0) at _cgo_export.c:75
75 crosscall2(_cgoexp_aa310533d643_increment_counter, &_cgo_a, 8, _cgo_ctxt);
77 _cgo_release_context(_cgo_ctxt);
(gdb) n
...
main (argc=1, argv=0x7fffffffdda8) at ./main.c:33
33 for(int i = 0; i < 1; i += 1){
36 printf("parent = %d\n", get_counter(ctx));
(gdb) n
次に 子プロセスです
$ gdb ./a.out -d _obj -d $(go env GOROOT) > set follow-fork-mode child > set detach-on-fork off > b _cgo_wait_runtime_init_done > run
n を繰り返していくと次のところで止まっていました
24 printf("run child\n");
25 for(int i = 0; i < 2; i += 1){
26 increment_counter(ctx);
(gdb) n
...
increment_counter (ctx=0x5555555593d0) at _cgo_export.c:75
75 crosscall2(_cgoexp_aa310533d643_increment_counter, &_cgo_a, 8, _cgo_ctxt);
(gdb) n
もう少し見てみます、次は crosscall2 を探します
$ gdb ./a.out -d _obj -d $(go env GOROOT) > set follow-fork-mode child > set detach-on-fork off > b crosscall2 > run
すると、次のところで止まっているようです
24 printf("run child\n");
25 for(int i = 0; i < 2; i += 1){
26 increment_counter(ctx);
(gdb) n
...
(gdb) info stack
#0 crosscall2 () at /usr/local/go/src/runtime/cgo/asm_amd64.s:22
#1 0x00007ffff7f036b0 in increment_counter (ctx=0x5555555593d0) at _cgo_export.c:75
#2 0x00005555555552f7 in main (argc=1, argv=0x7fffffffdda8) at ./main.c:26
#3 0x00007ffff7c9e083 in __libc_start_main () from /lib/x86_64-linux-gnu/libc.so.6
#4 0x000055555555518e in _start ()
Thread 2.1 "a.out" hit Breakpoint 1, crosscall2 () at /usr/local/go/src/runtime/cgo/asm_amd64.s:14
14 PUSH_REGS_HOST_TO_ABI0()
17 ADJSP $0x18
19 MOVQ DI, 0x0(SP) /* fn */
20 MOVQ SI, 0x8(SP) /* arg */
22 MOVQ CX, 0x10(SP) /* ctxt */
30 CALL runtime·cgocallback(SB)
何やらこのあたりに問題がありそうです *7
もう少し深掘りできそうですが、少し変えて
Go内で fork をした場合はどうでしょうか
package main /* #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> */ import "C" import ( "fmt" ) func bar(label string) { wait := make(chan struct{}) go func() { fmt.Printf("in goroutine %s\n", label) wait <- struct{}{} }() fmt.Printf("outer goroutine %s\n", label) <-wait } func main() { pid := C.fork() if pid == C.int(-1) { panic("failed to fork") } if pid == C.int(0) { bar("child") C.exit(C.int(0)) } else { bar("parent") } status := C.int(0) r := C.waitpid(-1, &status, C.WNOHANG) fmt.Println("exit", r) }
C で行っていたものを同じように Go の処理に置き換えてみたのですが
なんと、この場合は問題なく動きます
$ go run main.go outer goroutine child in goroutine child outer goroutine parent in goroutine parent exit 0
どうやら Go を外側から呼ぶ際には goroutine の初期化を終える必要がありそうです
確かめるため Go の処理を次のようにしました
package main /* #include <stdlib.h> */ import "C" import ( "runtime" ) var ( ch = make(chan struct{}) ) //export lock func lock() C.int { go func() { <-ch }() return C.int(runtime.NumGoroutine()) } //export unlock func unlock() C.int { ch <-struct{}{} return C.int(runtime.NumGoroutine()) } func init() { runtime.GOMAXPROCS(1) } func main() {}
runtime.GOMAXPROCS で 1つの CPU に変えつつ
チャンネルの読み込みを待つ関数 lock を用意しました
これで goroutine は、lock が呼ばれるたびに増え、unlockが呼ばれるたびに減るはずです
C を次のようにしました
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> #include "libmain.h" void main(int argc, char *argv[]) { for(int i = 0; i < 10; i += 1) { printf("[%d] lock %d\n", i, lock()); } for(int i = 0; i < 5; i += 1) { printf("[%d] unlock %d\n", i, unlock()); } pid_t pid = fork(); if(pid == -1) { exit(1); } if(pid == 0) { printf("child lock = %d\n", lock()); printf("child unlock = %d\n", unlock()); exit(0); } int status; for(int i = 0; i < 5; i += 1) { if((pid = waitpid(pid, &status, WNOHANG)) == -1) { exit(1); } if(pid == 0) { printf("child still running\n"); sleep(1); continue; } if(WIFEXITED(status)) { printf("child exit status=%d\n", WEXITSTATUS(status)); exit(0); } } printf("bye\n"); exit(0); }
これで、fork前は lock で goroutine が増え unlock で goroutine が減っているはずです
また fork 後に lock を呼び出して 新しい goroutine を起動する処理にしています
実行した結果は
$ gcc -g -I. -L. ./main.c -lmain && ./a.out [0] lock 2 [1] lock 3 [2] lock 4 [3] lock 5 [4] lock 6 [5] lock 7 [6] lock 8 [7] lock 9 [8] lock 10 [9] lock 11 [0] unlock 10 [1] unlock 9 [2] unlock 8 [3] unlock 7 [4] unlock 6 # ここまでが fork 前 child still running child lock = 7 child still running child still running child still running child still running bye
child lock = 7 と出ているため新しい goroutine が起動したようですが、その後の処理が進まずハングアップしているようです *8
golang の issue を探してみると https://github.com/golang/go/issues/53806 および https://github.com/golang/go/issues/14767 の issue に書いてあるように fork とマルチスレッドの組み合わせは失敗するようです
Unix Domain Socketの組み合わせ
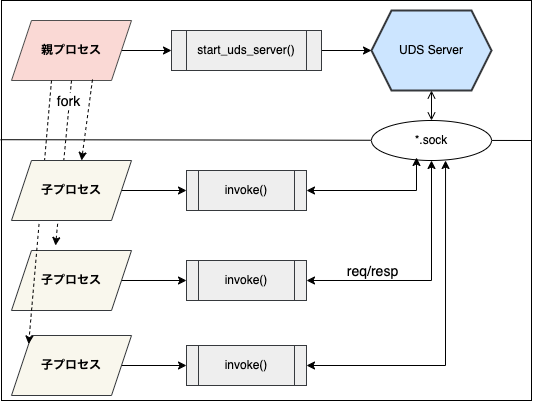
ここまでで分かったように、外部からforkされたものは、親プロセスでは処理が進むものの 子プロセスでは初期化が正常に完了せずハングアップするようです
ただし、親プロセス上では呼び出しが行えるようなので、子プロセスから親プロセスへどうにかしてプロセス間通信を行えば親プロセスのスレッド上で処理が実行できるはずです
そこで、Unix Domain Socket (以下UDS) を用いたIPC通信で、親プロセスで socket を開き、子プロセスから socket に対して通信するようにしてみようと考えました
UDS のソケットで実装しておけば、高パフォーマンスはもとより後々 TCP 等に切り替えた場合でも XS などのレイヤで透過的に移行もしやすいはずです
まずは確認のため Go の実装を次のように用意しました *9
package main /* #include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <sys/socket.h> #include <sys/un.h> #include <unistd.h> typedef struct uds_context_t { char* path; int path_len; uintptr_t listener; int counter; } uds_context_t; typedef struct uds_result_t { unsigned char* data; uint32_t data_len; } uds_result_t; static uds_result_t* uds_write_read( char* uds_path, int uds_path_len, unsigned char* header, int header_len, unsigned char* body, int body_len ) { int fd = socket(PF_UNIX, SOCK_STREAM, 0); if(fd < 0){ return NULL; } struct sockaddr_un addr; memset(&addr, 0, sizeof(struct sockaddr_un)); addr.sun_family = AF_UNIX; memcpy(addr.sun_path, uds_path, uds_path_len); if(connect(fd, (struct sockaddr *)&addr, sizeof(struct sockaddr_un)) < 0){ return NULL; } if(send(fd, header, header_len, 0) < 0){ return NULL; } if(send(fd, body, body_len, 0) < 0){ return NULL; } unsigned char resSize[4]; if(recv(fd, resSize, 4, 0) < 0){ return NULL; } // BE uint32 uint32_t size = ( (resSize[0] & 0xFF) << 24 | (resSize[1] & 0xFF) << 16 | (resSize[2] & 0xFF) << 8 | (resSize[3] & 0xFF) ); uds_result_t* out = (uds_result_t *)malloc(sizeof(uds_result_t)); out->data = (unsigned char*)malloc(size); if(recv(fd, out->data, size, 0) < 0){ return NULL; } out->data_len = size; close(fd); return out; } */ import "C" import ( "bytes" "encoding/binary" "encoding/json" "errors" "io" "net" "os" "strconv" "unsafe" ) //export create_uds_context func create_uds_context() (*C.uds_context_t, C.int) { f, err := os.CreateTemp("", "*.sock") if err != nil { return nil, C.int(-1) } f.Close() path := f.Name() os.Remove(path) s := C.size_t(C.sizeof_struct_uds_context_t) p := C.malloc(s) if p == nil { return nil, C.int(-1) } C.memset(p, 0, s) ctx := (*C.uds_context_t)(p) ctx.path = C.CString(path) ctx.path_len = C.int(len(path)) return ctx, C.int(0) } //export destroy_uds_context func destroy_uds_context(ctx *C.uds_context_t) { ln := *(**net.UnixListener)(unsafe.Pointer(uintptr(ctx.listener))) ln.Close() os.Remove(C.GoStringN(ctx.path, ctx.path_len)) C.free(unsafe.Pointer(ctx.path)) C.free(unsafe.Pointer(ctx)) } //export start_uds_server func start_uds_server(ctx *C.uds_context_t) C.int { path := C.GoStringN(ctx.path, ctx.path_len) ln, err := net.ListenUnix("unix", &net.UnixAddr{Name: path}) if err != nil { return C.int(-1) } ctx.listener = C.uintptr_t(uintptr(unsafe.Pointer(ln))) go runLoop(ctx, ln) return C.int(0) } type ( GoInput struct { FuncName string `json:"f"` Args []string `json:"a"` } GoOutput struct { OK bool `json:"ok"` Res string `json:"r"` } goFunc func(*C.uds_context_t, []string) (string, bool) ) var ( funcMap = map[string]goFunc{ "increment_counter": goIncrementCounter, } ) //export increment_counter func increment_counter(ctx *C.uds_context_t, num C.int) C.int { res, ok := invoke(ctx, "increment_counter", []string{strconv.Itoa(int(num))}) if ok != true { return C.int(-1) } v, _ := strconv.Atoi(res) return C.int(v) } func goIncrementCounter(ctx *C.uds_context_t, args []string) (string, bool) { num := 1 if 0 < len(args) { n, _ := strconv.Atoi(args[0]) num = n } ctx.counter += C.int(num) return strconv.Itoa(int(ctx.counter)), true } func invoke(ctx *C.uds_context_t, funcName string, args []string) (string, bool) { req := bytes.NewBuffer(nil) json.NewEncoder(req).Encode(GoInput{ FuncName: funcName, Args: args, }) reqData := req.Bytes() reqSize := uint32(len(reqData)) reqSizeData := make([]byte, 4) binary.BigEndian.PutUint32(reqSizeData, reqSize) out := C.uds_write_read( ctx.path, ctx.path_len, (*C.uchar)(unsafe.Pointer(&reqSizeData[0])), C.int(len(reqSizeData)), (*C.uchar)(unsafe.Pointer(&reqData[0])), C.int(len(reqData)), ) outData := unsafe.Slice((*byte)(out.data), int(out.data_len)) res := GoOutput{} json.NewDecoder(bytes.NewReader(outData)).Decode(&res) return res.Res, res.OK } func serverReadWrite(ctx *C.uds_context_t, conn net.Conn) { defer conn.Close() headerData, _ := readAll(conn, 4) reqSize := binary.BigEndian.Uint32(headerData) reqData, _ := readAll(conn, reqSize) in := GoInput{} json.NewDecoder(bytes.NewReader(reqData)).Decode(&in) fn := funcMap[in.FuncName] res, ok := fn(ctx, in.Args) buf := bytes.NewBuffer(nil) json.NewEncoder(buf).Encode(GoOutput{ OK: ok, Res: res, }) data := buf.Bytes() resSize := uint32(len(data)) resSizeData := make([]byte, 4) binary.BigEndian.PutUint32(resSizeData, resSize) writeAll(conn, resSizeData, 4) writeAll(conn, data, resSize) } func writeAll(w io.Writer, data []byte, size uint32) error { max := int64(size) total := int64(0) for { n, err := w.Write(data) if err != nil { return err } total += int64(n) if total == max { break } } return nil } func readAll(r io.Reader, size uint32) ([]byte, error) { max := int64(size) lim := io.LimitReader(r, max) out := bytes.NewBuffer(make([]byte, 0, size)) buf := make([]byte, 16*1024) total := int64(0) for { n, err := lim.Read(buf) if err != nil { if errors.Is(err, io.EOF) { break } return nil, err } out.Write(buf[:n]) total += int64(n) if total == max { break } } return out.Bytes(), nil } func runLoop(ctx *C.uds_context_t, ln net.Listener) { for { conn, err := ln.Accept() if err != nil { if err == net.ErrClosed { return } panic(err) } go serverReadWrite(ctx, conn) } } func main() {}
少し大きいですがやっていることは
- net.ListenUnix で UDS を 親プロセスで Listen
//exportした関数は 子プロセスから client として UDS に書き込み- 親プロセスで UDS を読み込み 呼び出された export の関数名から Go の関数を呼び出す
を行っています
コードを抜き出して説明していくと、UDS の Listen は下記のようにしていて、親プロセスなので通常の Go と同じように goroutine の起動もそのままです
//export start_uds_server func start_uds_server(ctx *C.uds_context_t) C.int { path := C.GoStringN(ctx.path, ctx.path_len) ln, err := net.ListenUnix("unix", &net.UnixAddr{Name: path}) if err != nil { return C.int(-1) } ctx.listener = C.uintptr_t(uintptr(unsafe.Pointer(ln))) go runLoop(ctx, ln) return C.int(0) }
//export した関数は 子プロセスから呼び出されることがあるため、直接 Goの関数を呼び出さず invoke という関数を通じて UDS で書き込んでます
//export increment_counter func increment_counter(ctx *C.uds_context_t, num C.int) C.int { res, ok := invoke(ctx, "increment_counter", []string{strconv.Itoa(int(num))}) if ok != true { return C.int(-1) } v, _ := strconv.Atoi(res) return C.int(v) }
invoke関数では、 JSON にエンコードしたデータを C.uds_write_read で UDS に書き込みます
ここで重要なのが CGO を経由して C で実行している点です
これは先程 fork の実験でもあったように、goroutine を呼び出そうとするとハングアップするため、CGO を通じて UDS を書き込みます
func invoke(ctx *C.uds_context_t, funcName string, args []string) (string, bool) { // データは Go で用意して req := bytes.NewBuffer(nil) json.NewEncoder(req).Encode(GoInput{ FuncName: funcName, Args: args, }) reqData := req.Bytes() reqSize := uint32(len(reqData)) reqSizeData := make([]byte, 4) binary.BigEndian.PutUint32(reqSizeData, reqSize) // CGO で UDS に書き込んでいる out := C.uds_write_read( ctx.path, ctx.path_len, (*C.uchar)(unsafe.Pointer(&reqSizeData[0])), C.int(len(reqSizeData)), (*C.uchar)(unsafe.Pointer(&reqData[0])), C.int(len(reqData)), ) outData := unsafe.Slice((*byte)(out.data), int(out.data_len)) res := GoOutput{} json.NewDecoder(bytes.NewReader(outData)).Decode(&res) return res.Res, res.OK }
親プロセスでは普通の UDS Serverとして実装しているため、Go の関数を直接実行しレスポンスを返しています
var ( funcMap = map[string]goFunc{ "increment_counter": goIncrementCounter, } ) func goIncrementCounter(ctx *C.uds_context_t, args []string) (string, bool) { num := 1 if 0 < len(args) { n, _ := strconv.Atoi(args[0]) num = n } ctx.counter += C.int(num) return strconv.Itoa(int(ctx.counter)), true } func serverReadWrite(ctx *C.uds_context_t, conn net.Conn) { defer conn.Close() headerData, _ := readAll(conn, 4) reqSize := binary.BigEndian.Uint32(headerData) reqData, _ := readAll(conn, reqSize) in := GoInput{} json.NewDecoder(bytes.NewReader(reqData)).Decode(&in) fn := funcMap[in.FuncName] res, ok := fn(ctx, in.Args) buf := bytes.NewBuffer(nil) json.NewEncoder(buf).Encode(GoOutput{ OK: ok, Res: res, }) data := buf.Bytes() resSize := uint32(len(data)) resSizeData := make([]byte, 4) binary.BigEndian.PutUint32(resSizeData, resSize) writeAll(conn, resSizeData, 4) writeAll(conn, data, resSize) }
それでは、実際に fork を行っても問題が無いか確認します
さきほど作った親プロセスと子プロセスの呼び出し確認のコードを今回の実装に合わせて下記のように修正しました
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> #include "libuds.h" void main() { struct create_uds_context_return ret = create_uds_context(); if(ret.r1 != 0) { exit(1); } uds_context_t* ctx = ret.r0; // 親プロセスで起動 if(start_uds_server(ctx) != 0) { exit(1); } pid_t pid = fork(); if(pid == -1) { exit(1); } if(pid == 0) { for(int i = 0; i < 10; i += 1){ increment_counter(ctx, 1); } printf("child increment = %d\n", increment_counter(ctx, 10)); exit(0); } int status; for(int i = 0; i < 5; i += 1) { if((pid = waitpid(pid, &status, WNOHANG)) == -1) { exit(1); } if(pid == 0) { printf("child still running\n"); sleep(1); continue; } if(WIFEXITED(status)) { printf("child exit status=%d\n", WEXITSTATUS(status)); break; } } printf("parent increment = %d\n", increment_counter(ctx, 1)); destroy_uds_context(ctx); }
これの実行結果は
$ gcc -g -I. -L. ./run.c -luds && ./a.out child still running child increment = 20 child exit status=0 parent increment = 21
となり実行できるようです
また、副作用というか利点になるのかもしれませんが fork と違い UDS を通じて親プロセスでの計算結果になったため、値が共有されるようになっています
UDS + XS のパフォーマンス
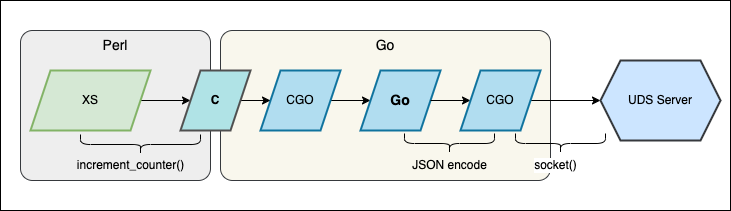
fork 後でも動作するようになったので、UDS 対応したものを使って XS の呼び出しのパフォーマンスを見てみます
これも最初に使った簡単なベンチマークを使って確認します
use strict; use Benchmark qw/timethese/; use MyXS; my $ctx = MyXS->create(); $ctx->init(); timethese(-10, { md5_xsuds => sub { $ctx->md5("hoge"); }, ack_xsuds => sub { $ctx->ack(3, 4); }, one_xsuds => sub { $ctx->one(); } });
これの結果は次のようになりました
Benchmark: running ack_xsuds, md5_xsuds, one_xsuds for at least 10 CPU seconds... ack_xsuds: 10 wallclock secs ( 5.33 usr + 5.31 sys = 10.64 CPU) @ 8080.36/s (n=85975) md5_xsuds: 10 wallclock secs ( 3.18 usr + 7.34 sys = 10.52 CPU) @ 11355.42/s (n=119459) one_xsuds: 10 wallclock secs ( 3.04 usr + 7.44 sys = 10.48 CPU) @ 11508.40/s (n=120608)
前回取ったものからどれだけ変化しているかというと
UDS後の軽量の関数呼び出し
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接one() | 1000000000 | 1.0000 (100%) |
| XSでのone() | 82340095 | 0.0823 (8.23%) |
| UDSでのone() | 120608 | 0.0001 (0.01%) |
XS で呼び出した one() は 約124ns/call でしたが UDS で呼び出した one() は
11508.40/s = 86893ns = 86us/call となりました
ほぼ何も処理をしていない関数の呼び出しなので、 XS 経由 & UDS によるオーバーヘッドと考えられます
UDS後のアッカーマン関数の比較
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接ack(3,4) | 381193 | 1.0000 (100%) |
| Perlのack(3,4) | 9163 | 0.0240 (2.40%) |
| XSでのack(3,4) | 345247 | 0.9057 (90.57%) |
| UDSでのack(3,4) | 85975 | 0.2255 (22.55%) |
こちらも XS の呼び出しは劣化しますが、Perlでのアッカーマン計算よりは速いようです
計算量の多い場面では UDS 経由でも有利そうです
UDS後のMD5関数の比較
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接md5 | 90010182 | 1.0000 (100%) |
| Digest::MD5 | 62354637 | 0.6927 (69.27%) |
| XSでのmd5 | 21376748 | 0.2374 (23.74%) |
| UDSでのmd5 | 119459 | 0.0013 (0.13%) |
11355.42/s = 88063ns = 88.06us となり、軽量の関数呼び出しと差があまりでない結果となりました
元の md5 の計算が軽量(128ns)であるのもありますが、おおよそ 90us 程度が UDS によるオーバーヘッドとなりそうです
UDS後のベンチマークからわかること
このことから次のことが分かりました
XS -> CGOの呼び出し同様に UDS でも軽量の関数呼び出しには向いていないXS -> CGOでは ナノ秒のオーダだったのが マイクロ秒まで跳ね上がる
今回の実装では XS から Go(CGO) を通じて UDS を呼び出しているため CGO による呼び出しが含まれています
また C -> Go の呼び出しによる goroutine の初期化問題もあるため、もう少し チューニングできそうです
XS 上で直接 UDS を読み書きする
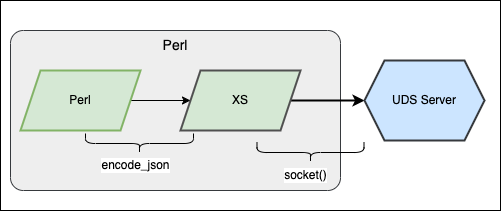
これまでの実装では XS -> C -> GO -> CGO と呼び出しの階層が深くなっています
UDS でのペイロードは 4 バイトのヘッダ + JSON とシンプルな形式なので、XSでも取り扱いしやすいはずです
そこで直接 XS で UDS を読み書きできればもう少しパフォーマンスが改善するかもしれません
XS に _invoke(ctx, json) の関数を追加し UDS を読み書きする uds_invoke を加えました
void _invoke(ctx, json) myxs_context_t *ctx; SV* json; PROTOTYPE: $$ PPCODE: { const char* data; STRLEN len; SvGETMAGIC(json); if(SvOK(json)) { data = SvPV(json, len); } else { croak("failed to call _invoke: json"); } uds_result_t* resp = uds_invoke( ctx->path, ctx->path_len, data, len ); EXTEND(SP,2); if(NULL == resp) { int ok = -1; XPUSHs(sv_2mortal(&PL_sv_undef)); XPUSHs(sv_2mortal(newSViv(ok))); XSRETURN(2); return; } if(resp->ok != 0) { XPUSHs(sv_2mortal(&PL_sv_undef)); XPUSHs(sv_2mortal(newSViv(resp->ok))); XSRETURN(2); Safefree(resp); return; } SV* response = newSVpv(resp->data, resp->data_len); XPUSHs(sv_2mortal(response)); XPUSHs(sv_2mortal(newSViv(resp->ok))); XSRETURN(2); Safefree(resp); }
送信周り (uds_invoke) は次のようにしています *10
#include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <sys/socket.h> #include <sys/un.h> #include <unistd.h> typedef struct uds_result_t { unsigned char* data; uint32_t data_len; int ok; } uds_result_t; static void write_header(unsigned char* data, int len) { unsigned char sizeData[4]; memset(&sizeData, 0, 4); // write BE32 uint32_t size = (uint32_t) len; sizeData[0] = (unsigned char) (size >> 24); sizeData[1] = (unsigned char) (size >> 16); sizeData[2] = (unsigned char) (size >> 8); sizeData[3] = (unsigned char) (size); memcpy(data, sizeData, 4); } static unsigned char* make_packet(const char* json, int json_len) { int packet_size = json_len + 4; unsigned char* packet = (unsigned char*) malloc(packet_size); if(NULL == packet) { return NULL; } unsigned char* header = packet + 0; write_header(header, json_len); unsigned char* payload = packet + 4; memcpy(payload, json, json_len); return packet; } static int send_all(int fd, unsigned char* src, size_t size) { size_t total_send = 0; while (total_send < size) { size_t send_size = send(fd, src + total_send, size - total_send, 0); if(send_size < 0) { return -1; } if(send_size == 0) { break; } total_send += send_size; } if(total_send != size) { return -1; } return 0; } static int recv_all(int fd, unsigned char* dst, size_t size) { size_t total_received = 0; while (total_received < size) { size_t recv_size = recv(fd, dst + total_received, size - total_received, 0); if(recv_size < 0) { return -1; } if(recv_size == 0) { break; } total_received += recv_size; } if(total_received != size) { return -1; } return 0; } static uds_result_t* uds_invoke( char *uds_sock_path, int uds_sock_path_len, const char* request_json, int request_json_len ) { uds_result_t* res = (uds_result_t*) malloc(sizeof(uds_result_t)); if(NULL == res) { return NULL; } memset(res, 0, sizeof(uds_result_t)); unsigned char* packet = make_packet(request_json, request_json_len); if(NULL == packet) { res->ok = -1; return res; } size_t packet_len = request_json_len + 4; // 4 = header size int fd = socket(PF_UNIX, SOCK_STREAM, 0); if(fd < 0) { res->ok = -1; return res; } struct sockaddr_un addr; memset(&addr, 0, sizeof(struct sockaddr_un)); memcpy(addr.sun_path, uds_sock_path, uds_sock_path_len); addr.sun_family = AF_UNIX; if(connect(fd, (struct sockaddr *)&addr, sizeof(struct sockaddr_un)) < 0){ res->ok = -1; return res; } if(send_all(fd, packet, packet_len) < 0){ res->ok = -1; return res; } free(packet); unsigned char res_size[4]; if(recv_all(fd, res_size, 4) < 0){ res->ok = -1; return res; } // BE uint32 uint32_t res_packet_size = ( (res_size[0] & 0xFF) << 24 | (res_size[1] & 0xFF) << 16 | (res_size[2] & 0xFF) << 8 | (res_size[3] & 0xFF) ); res->data = (unsigned char*) malloc(res_packet_size); if(NULL == res->data) { res->ok = -1; return res; } if(recv_all(fd, res->data, res_packet_size) < 0){ res->ok = -1; return res; } close(fd); res->ok = 0; res->data_len = res_packet_size; return res; }
Perl のモジュールは JSON::XS で直接ペイロードのJSONを作成して呼び出すように変更します
sub one { my $self = shift; my $payload = +{ f => 'one', a => [] }; return $self->xs_invoke($payload); } sub ack { my $self = shift; my ($m, $n) = @_; my $payload = +{ f => 'ack', a => ["$m", "$n"] }; return $self->xs_invoke($payload); } sub md5 { my $self = shift; my ($str) = @_; my $payload = +{ f => 'md5', a => [$str] }; return $self->xs_invoke($payload); } sub xs_invoke { my $self = shift; my ($payload) = @_; my ($res_json, $ok) = _invoke($self->{ctx}, encode_json($payload)); if($ok != 0) { croak("failed to call $payload->{f}"); } my $out = decode_json($res_json); return undef unless($out->{ok}); return $out->{r}; }
これのベンチマークの結果は次のようになりました
Benchmark: running ack_uds, md5_uds, one_uds for at least 10 CPU seconds... ack_uds: 10 wallclock secs ( 4.69 usr + 5.84 sys = 10.53 CPU) @ 7435.04/s (n=78291) md5_uds: 9 wallclock secs ( 3.28 usr + 7.41 sys = 10.69 CPU) @ 11503.55/s (n=122973) one_uds: 9 wallclock secs ( 3.39 usr + 7.28 sys = 10.67 CPU) @ 11525.40/s (n=122976)
直接 XS から UDS を読み書きするようになった結果をまとめると次のようになります
直接UDS読み書きの軽量の関数呼び出し
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接one() | 1000000000 | 1.0000 (100%) |
| XSでのone() | 82340095 | 0.0823 (8.23%) |
| UDSでのone() | 120608 | 0.0001 (0.01%) |
| 直接UDSのone() | 122976 | 0.0001 (0.01%) |
回数でいくと若干改善していますが、速度でみると 11525.40/s = 86us とあまり大きく改善はしていません
UDSによるオーバーヘッドがこれくらいと見て良さそうです
直接UDS読み書きのアッカーマン関数の比較
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接ack(3,4) | 381193 | 1.0000 (100%) |
| Perlのack(3,4) | 9163 | 0.0240 (2.40%) |
| XSでのack(3,4) | 345247 | 0.9057 (90.57%) |
| UDSでのack(3,4) | 85975 | 0.2255 (22.55%) |
| 直接UDSのack(3,4) | 78291 | 0.2053 (20.53%) |
こちらは回数でみると悪化しているように見えますが、速度で比べてみると大きな有意差はありません
直接UDS読み書きのMD5関数の比較
| 呼び出し方法 | Count | rate |
|---|---|---|
| Goで直接md5 | 90010182 | 1.0000 (100%) |
| Digest::MD5 | 62354637 | 0.6927 (69.27%) |
| XSでのmd5 | 21376748 | 0.2374 (23.74%) |
| UDSでのmd5 | 119459 | 0.0013 (0.13%) |
| 直接UDSでのmd5 | 122973 | 0.0013 (0.13%) |
こちらも軽量の関数呼び出しと同じ結果で、若干回数で見ると良いですが 11503.55/s = 86us となり UDS のオーバーヘッドは超えられなさそうです
直接UDS読み書きのベンチマークから分かること
- CGO を経由していても、そこまでパフォーマンスに影響を与えていたわけではなかった
- 逆に
JSON::XSを使いながら Perl に近い領域で実装しても、パフォーマンスの劣化には繋がっていなかった
ということが分かりました
イベントループ UDS にする
現在の実装は net.UnixListener を使用していて、 Accept() 後には goroutine を用いた並列処理を行っているのですが
イベントループ系(epoll等)で実装されているライブラリがあり、高速化される可能性があります
cloudwego/netpoll を使って実装し直しました
package main /* #include <stdlib.h> #include <stdint.h> #include <string.h> typedef struct myxs_context_t { char* path; int path_len; uintptr_t cancel; } myxs_context_t; */ import "C" ... //export destroy_myxs_context func destroy_myxs_context(ctx *C.myxs_context_t) { cancel := *(*context.CancelFunc)(unsafe.Pointer(uintptr(ctx.cancel))) cancel() os.Remove(C.GoStringN(ctx.path, ctx.path_len)) C.free(unsafe.Pointer(ctx.path)) C.free(unsafe.Pointer(ctx)) } //export start_myxs_server func start_myxs_server(ctx *C.myxs_context_t) C.int { path := C.GoStringN(ctx.path, ctx.path_len) listener, err := netpoll.CreateListener("unix", path) if err != nil { return C.int(-1) } evtloop, err := netpoll.NewEventLoop(func(_ context.Context, conn netpoll.Connection) error { return serverReadWrite(ctx, conn) }) if err != nil { return C.int(-1) } c, f := context.WithCancel(context.Background()) go func() { <-c.Done() evtloop.Shutdown(context.TODO()) listener.Close() }() go func() { evtloop.Serve(listener) }() ctx.cancel = C.uintptr_t(uintptr(unsafe.Pointer(&f))) return C.int(0) } ... func serverReadWrite(ctx *C.myxs_context_t, conn netpoll.Connection) error { defer conn.Close() reader := conn.Reader() defer reader.Release() msgLen, err := reader.Peek(4) if err != nil { return err } dataLen := int(binary.BigEndian.Uint32(msgLen)) + 4 data, err := reader.ReadBinary(dataLen) if err != nil { return err } in := GoInput{} if err := json.NewDecoder(bytes.NewReader(data[4:])).Decode(&in); err != nil { return err } fn := funcMap[in.FuncName] res, ok := fn(ctx, in.Args) buf := pool.Get().(*bytes.Buffer) defer pool.Put(buf) buf.Reset() if err := json.NewEncoder(buf).Encode(GoOutput{ OK: ok, Res: res, }); err != nil { return err } outData := buf.Bytes() writer := conn.Writer() out, err := writer.Malloc(4 + len(outData)) if err != nil { return err } binary.BigEndian.PutUint32(out[0:4], uint32(len(outData))) copy(out[4:], outData) if err := writer.Flush(); err != nil { return err } return nil } func init() { netpoll.Initialize() netpoll.DisableGopool() } func main() {}
さて、こちらのベンチマークなのですが下記のようになっており、 標準パッケージのものとあまり変わっていません
Benchmark: running ack_uds, md5_uds, one_uds for at least 10 CPU seconds... ack_uds: 9 wallclock secs ( 5.56 usr + 4.73 sys = 10.29 CPU) @ 7124.30/s (n=73309) md5_uds: 9 wallclock secs ( 3.94 usr + 6.99 sys = 10.93 CPU) @ 9389.11/s (n=102623) one_uds: 10 wallclock secs ( 4.13 usr + 7.40 sys = 11.53 CPU) @ 9142.32/s (n=105411)
それもそのはずで、イベントループの効果が大きいのは並列実行を伴うテストになるはずです
Parallel::ForkManager を使って次のようにテストを用意し
use Parallel::ForkManager; use Statistics::Descriptive; my $xs = MyXS->new(); $xs->init; sub bench { my ($name, $cb, $conc_list) = @_; my $N = 1000; for my $conc (@$conc_list) { my $stat = Statistics::Descriptive::Full->new(); my $pm = Parallel::ForkManager->new($conc); $pm->run_on_finish(sub{ my ($p, $c, $i, $s, $d, $data) = @_; $stat->add_data($data->{elapse}); }); for (1 .. $conc) { $pm->start and next; my $start = Time::HiRes::time(); $cb->(); my $elapse = Time::HiRes::time() - $start; $pm->finish(0, +{ elapse => $elapse }); } $pm->wait_all_children; my ($val, $idx) = $stat->percentile(95); printf( "%s(%3d) min/avg/max/95/stdev = %d/%d/%d/%d/%d us\n", $name, $conc, $stat->min() * 1000 * 1000, $stat->mean() * 1000 * 1000, $stat->max() * 1000 * 1000, $val * 1000 * 1000, $stat->standard_deviation() * 1000 * 1000, ); } print "\n"; } bench("cloudwego/netpoll/md5", sub { $xs->md5("hoge") }, [100, 500, 1000]); bench("cloudwego/netpoll/ack", sub { $xs->ack(3, 4) }, [100, 500, 1000]); bench("cloudwego/netpoll/one", sub { $xs->one() }, [100, 500, 1000]);
標準パッケージと cloudwego/netpoll でベンチマークしてみました
go/net/md5(100) min/avg/max/95/stddev = 272/2193/14618/8421/2647 us go/net/md5(500) min/avg/max/95/stddev = 213/949/4536/1854/577 us go/net/md5(1000) min/avg/max/95/stddev = 207/1019/6189/2871/864 us go/net/ack(100) min/avg/max/95/stddev = 298/1392/6515/2897/1010 us go/net/ack(500) min/avg/max/95/stddev = 249/1314/10154/3544/1315 us go/net/ack(1000) min/avg/max/95/stddev = 253/1245/10133/3854/1162 us go/net/one(100) min/avg/max/95/stddev = 236/1477/7669/3558/1270 us go/net/one(500) min/avg/max/95/stddev = 205/1111/7069/3000/995 us go/net/one(1000) min/avg/max/95/stddev = 216/943/6026/1994/688 us cloudwego/netpoll/md5(100) min/avg/max/95/stddev = 274/2035/9475/7568/2148 us cloudwego/netpoll/md5(500) min/avg/max/95/stddev = 212/1111/7914/2460/984 us cloudwego/netpoll/md5(1000) min/avg/max/95/stddev = 194/890/4695/1791/500 us cloudwego/netpoll/ack(100) min/avg/max/95/stddev = 273/1507/4077/3723/970 us cloudwego/netpoll/ack(500) min/avg/max/95/stddev = 252/1119/5777/2064/741 us cloudwego/netpoll/ack(1000) min/avg/max/95/stddev = 236/1038/7544/1996/729 us cloudwego/netpoll/one(100) min/avg/max/95/stddev = 295/1392/3681/2757/840 us cloudwego/netpoll/one(500) min/avg/max/95/stddev = 190/1039/6561/2096/801 us cloudwego/netpoll/one(1000) min/avg/max/95/stddev = 180/928/5766/1839/589 u
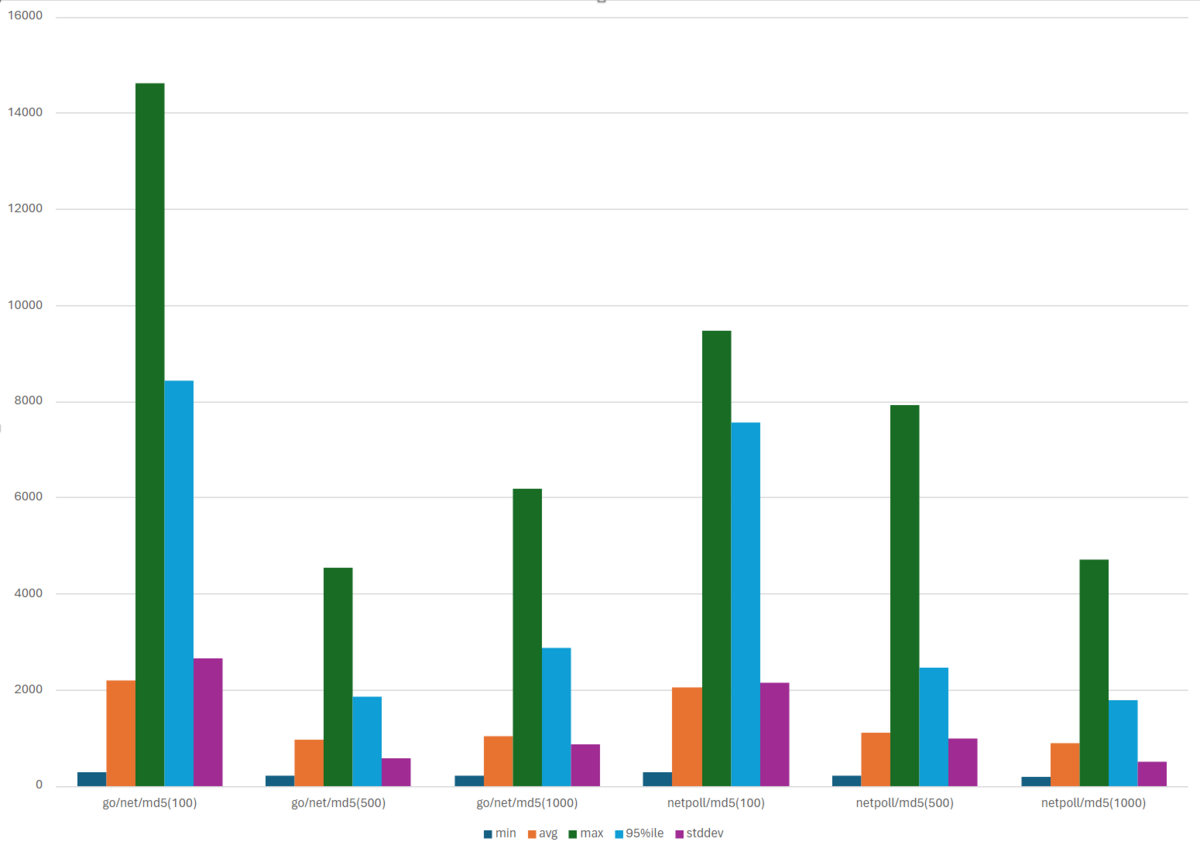
少し見づらいので md5,ack をグラフにしてみました

このベンチマークから分かること
- 標準パッケージを使用しているものは並列数が増えるとパフォーマンスが劣化しやすい
- netpoll を使用したものは並列数が多いほどパフォーマンスが劣化しにくい、もしくは高い傾向にありそう
ということでしょうか、実装自体そこまで変わらないので cloudwego/netpoll で UDS の処理を書くのが良さそうです
ローカルホストTCPとUDSの違いはあるか
さて、ここまでUDSを扱って来ましたが、ローカルホストで Listen する TCP との違いも見ておきたいです
特にシステム上どこのメトリクスが影響するのか見ておきます
計測を始める前に perf stat を使えるようにセットアップします
$ sudo apt install linux-tools-common linux-tools-generic
また 非特権ユーザからアクセスをできるよう -1 にします
$ sudo sh -c 'echo -1 > /proc/sys/kernel/perf_event_paranoid'
今回は Go の標準パッケージを使用した実装で ping/pong を 500並列で 10000回行ってみた結果を見てみます
コードは次のようにしました
package main import ( "encoding/binary" "flag" "fmt" "io" "net" "os" "sync" "time" "github.com/montanaflynn/stats" ) func main() { var mode string flag.StringVar(&mode, "m", "uds", "") flag.Parse() N := 10000 CONC := 500 ln, err := listen(mode) if err != nil { panic(err) } go acceptLoop(ln, pong) addr := ln.Addr().String() wg := new(sync.WaitGroup) wg.Add(CONC) ch := make(chan []time.Duration, CONC) for i := 0; i < CONC; i += 1 { go func(wg *sync.WaitGroup) { defer wg.Done() conn, err := dial(mode, addr) if err != nil { panic(err) } ch <- ping(conn, 0, N) }(wg) } wg.Wait() close(ch) total := make([]time.Duration, 0, CONC*N) for dur := range ch { total = append(total, dur...) } data := stats.LoadRawData(total) min, _ := data.Min() avg, _ := data.Mean() max, _ := data.Max() p50, _ := data.Percentile(0.50) p95, _ := data.Percentile(0.95) p99, _ := data.Percentile(0.99) stddev, _ := data.StandardDeviation() fmt.Printf( "min/avg/max/p50/p95/p99/stddev: %s/%s/%s/%s/%s/%s/%s\n", time.Duration(min), time.Duration(avg), time.Duration(max), time.Duration(p50), time.Duration(p95), time.Duration(p99), time.Duration(stddev), ) } func listen(mode string) (net.Listener, error) { if mode == "tcp" { addr, err := net.ResolveTCPAddr("tcp", "[0.0.0.0]:0") if err != nil { return nil, err } return net.ListenTCP("tcp4", addr) } f, err := os.CreateTemp("", "*.sock") if err != nil { panic(err) } f.Close() path := f.Name() os.Remove(path) addr, err := net.ResolveUnixAddr("unix", path) if err != nil { return nil, err } return net.ListenUnix("unix", addr) } func acceptLoop(ln net.Listener, handler func(net.Conn)) { defer ln.Close() for { conn, err := ln.Accept() if err != nil { panic(err) } go handler(conn) } } func pong(conn net.Conn) { defer conn.Close() buf := make([]byte, 10) for { if _, err := conn.Read(buf); err != nil { if err == io.EOF { return } panic(err) } dataLen := int(binary.BigEndian.Uint16(buf[0:2])) counter := binary.BigEndian.Uint64(buf[2 : 2+dataLen]) binary.BigEndian.PutUint16(buf[0:2], 8) binary.BigEndian.PutUint64(buf[2:10], counter+1) if _, err := conn.Write(buf); err != nil { panic(err) } } } func dial(mode, addr string) (net.Conn, error) { if mode == "tcp" { r, err := net.ResolveTCPAddr("tcp", addr) if err != nil { return nil, err } return net.DialTCP("tcp", nil, r) } r, err := net.ResolveUnixAddr("unix", addr) if err != nil { return nil, err } return net.DialUnix("unix", nil, r) } func ping(conn net.Conn, counter uint64, n int) []time.Duration { defer conn.Close() res := make([]time.Duration, n) buf := make([]byte, 10) for i := 0; i < n; i += 1 { s := time.Now() binary.BigEndian.PutUint16(buf[0:2], 8) binary.BigEndian.PutUint64(buf[2:10], counter) if _, err := conn.Write(buf); err != nil { panic(err) } if _, err := conn.Read(buf[0:10]); err != nil { panic(err) } dataLen := int(binary.BigEndian.Uint16(buf[0:2])) serverCounter := binary.BigEndian.Uint64(buf[2 : dataLen+2]) if serverCounter != (counter + 1) { panic("not same counter") } counter = serverCounter res[i] = time.Since(s) } return res }
これを perf stat で UDS の呼び出しを見てみます
$ perf stat -a --all-kernel -e cpu-clock,cpu-migrations,context-switches ./test
min/avg/max/p50/p95/p99/stddev: 2.325µs/279.971µs/140.996987ms/15.639µs/19.945µs/20.291µs/1.310217ms
Performance counter stats for 'system wide':
72748.20 msec cpu-clock # 15.999 CPUs utilized
202 cpu-migrations # 2.777 /sec
12807 context-switches # 176.046 /sec
4.546996533 seconds time elapsed
続いて TCP の呼び出しです
$ perf stat -a --all-kernel -e cpu-clock,cpu-migrations,context-switches ./test -m tcp
min/avg/max/p50/p95/p99/stddev: 3.683µs/296.241µs/99.78003ms/26.23µs/33.952µs/34.526µs/754.449µs
Performance counter stats for 'system wide':
74984.58 msec cpu-clock # 15.999 CPUs utilized
1464 cpu-migrations # 19.524 /sec
35903 context-switches # 478.805 /sec
4.686947886 seconds time elapsed
context-switches の数をみて分かるように UDS の方が2-3倍程度少ないことが分かります
またレイテンシですが
UDS が min/avg/max/p50/p95/p99/stddev: 2.325µs/279.971µs/140.996987ms/15.639µs/19.945µs/20.291µs/1.310217ms であるのに対して
TCP は min/avg/max/p50/p95/p99/stddev: 3.683µs/296.241µs/99.78003ms/26.23µs/33.952µs/34.526µs/754.449µs となっており
95%ile, 99%ile 値でUDSの方が良い結果を出すようです
続いて softirq の値もみてみます
まずは UDS です
$ perf stat -a -e irq:softirq_entry ./test
min/avg/max/p50/p95/p99/stddev: 2.314µs/77.311µs/145.878944ms/11.46µs/13.658µs/13.822µs/349.035µs
Performance counter stats for 'system wide':
922 irq:softirq_entry
1.192759865 seconds time elapsed
そして TCP です
$ perf stat -a -e irq:softirq_entry ./test -m tcp
min/avg/max/p50/p95/p99/stddev: 3.583µs/53.12µs/146.23349ms/8.037µs/8.762µs/8.823µs/437.196µs
Performance counter stats for 'system wide':
2001527 irq:softirq_entry
0.933401235 seconds time elapsed
かなりの差がある結果となりました
UDS を使うことで TCP と比べるとこのあたりのパフォーマンスが良い結果になりそうです
まとめ
いくつかのベンチマークを見て、次のことが言えそうです
- fork を伴わない Perl の環境では
XS -> CGOの呼び出しが最もパフォーマンスが良い - fork を伴う Perl の環境では
XS -> UDSの呼び出しがパフォーマンスはある程度落ちるが、イベントループ実装などに切り替えることで並列実行時のパフォーマンスを維持できる - ローカルホストの TCP でも大きなパフォーマンス劣化は見受けられないが、コンテキストスイッチ回数などが多く CPU 負荷は若干大きくなる
Mirrativ では fork を伴う環境であるため、2番目の XS -> UDS の実装を利用することにしました
また、既に一部本番環境では導入が始まっており、少しずつ機能の移行を行っています
今回 UDS を使って、異なるプログラミング言語同士での連携を紹介しましたが、配信音声文字起こしでも PythonとGoでUDSを使って実行 する実装になっています
開発の時間軸では先にこの Perl と Go の連携である程度パフォーマンス上の影響が少ないことを確認できていたため、Pythonの実装にも UDS を使うようにしていました
UDS を使ったIPCは各サービスで同じような作りになっているのでライブラリ化したり、もう少し抽象度を上げた実装にしていくのも今後行っていこうと思います
We are Hiring!
旧環境から新環境へ高パフォーマンスで連携できる仕組みを一緒に開発してくれるメンバーを募集しています!
*1:memcached関連の開発はさまざまな理由で別機能で実装しているので、改めて別記事で紹介します
*2:他にもデプロイフローの複雑化や内外からリクエストが届くことでの負荷分散の複雑性...etc課題があります
*3:実際の値は生成される libmyxs.h を確認ください
*4:アルゴリズムの最適化の余地は一旦抜きとしてます
*5:当たり前ですがパフォーマンスを気にする場面では、もっと詳細にベンチマークを取る必要があります
*6:本家のGDBを使ったGoのデバッグ紹介 を読みつつ一通り作業できるようになっていると便利です
*7:なお _cgo_wait_runtime_init_done は runtime/cgo/gcc_libinit.c に定義されています
*8:なお、たまにうまく動く場合もあるので、やはり初期化まわりが問題がありそうです
*9:エラー処理は長くなるので省いています
*10: こちらもエラー処理は削っているので色々と読み替えてください