
こんにちは ハタ です。
Mirrativのインフラ内で実際に開発・運用している内製のRedisサーバについてお話したいなと思っています。
前回の記事 は、今回紹介する内製Redisサーバで起きたメモリリーク対策に関するお話しとなっておりますので、もし未読であればあわせて読んでいただければと思います。
今回はなぜ Redis サーバを内製することにしたのかの経緯や実装についての簡単な紹介が出来たらなと思っています
Redis 導入の経緯
Mirrativ のインフラの基盤構成は、 Linux + MySQL + memcached + consul という構成で長年運用しており、基本的に全ての永続化するデータ構造は MySQL で実装し、cache用途で memcached を使用する形で Mirrativ のサービスを作ってきました
MySQLはとても高品質で安定しており、冗長化構成および HA ツールとしての MHA (以前紹介した記事はこちら)を使用した運用ノウハウはそれなりに蓄積できている状態なのですが、ちゃんと運用しようとしていると、運用コスト(手を動かしたりする場面や学習コストも含めて)がそれなりに高い課題があります
またmemcachedも併用していますが、データは揮発するため永続化のためにはMySQLも併用しなければならなかったり、逆に不要になったデータはMySQLから削除しなければいけなかったりと、アプリケーションの実装コストにおいてもそれなりに課題がありました
課題感: 揮発しないでほしい
Mirrativ の HTTP Session は、 memcached + MySQL で運用しており、MySQL上には SessionIDとそれに紐づくValueとExpirationを持つテーブルとオフロードのためのmemcached(KV)で構成しています
memcached 上で揮発しても 永続化している MySQL に問い合わせることで Session 切れずに(ログアウトされずに)サービスを利用できます
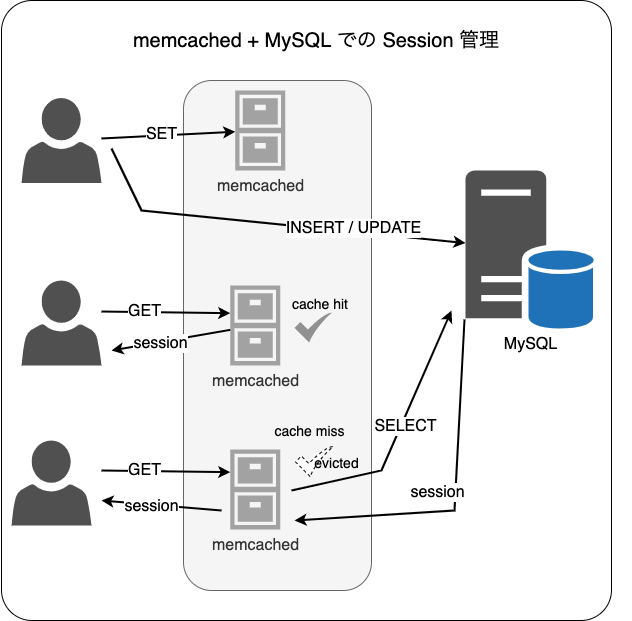
この場合必ず MySQL が必要かというと、要件次第ですがそうでもないのかなと思います
HTTP Sessionのようにデータが非常に小さく書き込みよりも読み込みが多い場合は、分散したmemcachedのメモリ上から返すことがほとんとですが、たまに突発的なアクセス数の増加などで Eviction が発生することもあるため、永続化してあるMySQLが必要となっていました
インフラ的な課題としては、Sessionというデータサイズが比較的小さいことからbuffer poolやサイジング等のチューニングを行いコスト最適化を行いつつも、MySQLの可用性を高めるために3ゾーン構成(+backupの構成)を取るとどうしても一定以上のコストが発生し最適化が難しいことなどがありました
課題感: 生存時間が短いデータを保持したい
生存時間が短いデータもMySQLで運用する上での課題と感じていました
Mirrativ のライブ配信という性質上、ライブ配信を行っている最中にしか使用しない(ライブが終わったら更新しなくなる)データがいくつか存在します
ライブ配信中の視聴閲覧数のデータや公式クイズ配信で使用する回答時のデータ(視聴者が選んだ設問のデータ)など、配信中にはデータが更新されますが、配信終了後の一定期間後には使われなくなるようなデータです
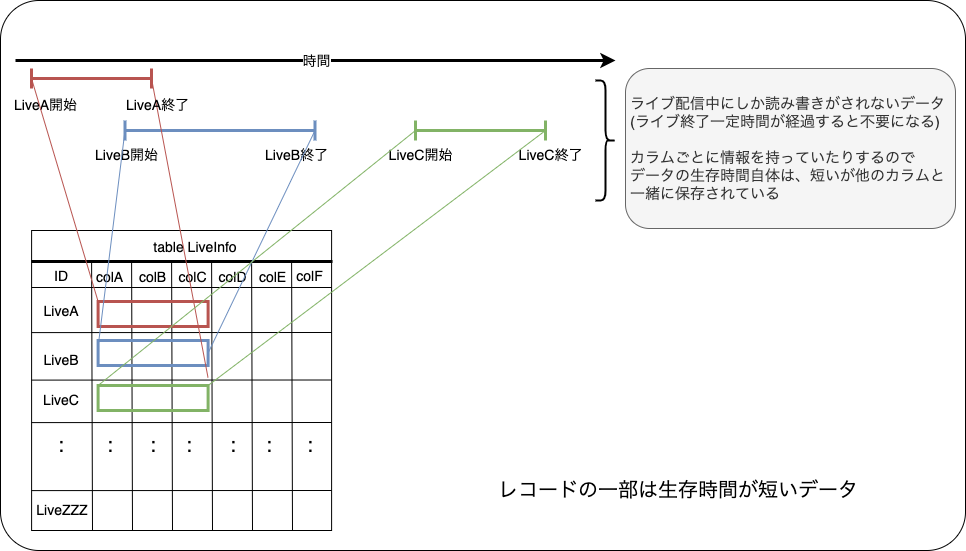
これらは配信が行われている数時間だけ書き込まれるデータであること、書き込みを行う流量が比較的多い(書き込みが集中する)ことなどから、memcachedを主に利用したりしていました
この要件を満たすようにMySQLで構成することもできるのですが、高いIO性能が求められることや常時使うものではなく非常に短期間のデータであることなどから、memcachedのeviction監視や流量の監視などを拡充させ安定して利用できるようにし、MySQLを使用しないようにしていました
課題感: 日次データをなんとかしたい
Mirrativ内のお知らせデータやイベントで利用するランキングなどのデータも課題を感じていました
Mirrativ内のお知らせデータは「○○さんにフォローされました」や「○○キャンペーンのお知らせ」...etcなどの各ユーザさんそれぞれに表示されるレコードを保持していて、 掲載期間の90日以上前のレコードは不要になるレコードです
イベント関連のレコードも同様で、イベント終了後一定期間が過ぎた際には不要になるデータです
これらはMySQLで実装してるのですが、短期的な運用であれば問題は無いのかなと思いますが、長期間の運用となると課題がいくつか出てきました
- IO性能
- 断片化/肥大化
- パーティション
- CREATE TABLE DATA DIRECTORY + DISK Attach
ランキングにもいろいろ種類があるのですが、デイリーランキングのようなタイプのものであれば ユーザ数 * 日数 のレコード数が作成されることになります。
不要になったデータは表領域確保のために削除するのですが、ものによっては 数十万レコードから数百万レコードを削除することになります
一度にこれだけのレコードを削除するには、それなりのIO性能が必要になったり削除中のレプリケーション遅延も考慮する必要があるため、ゆっくり削除するための実装が必要です。
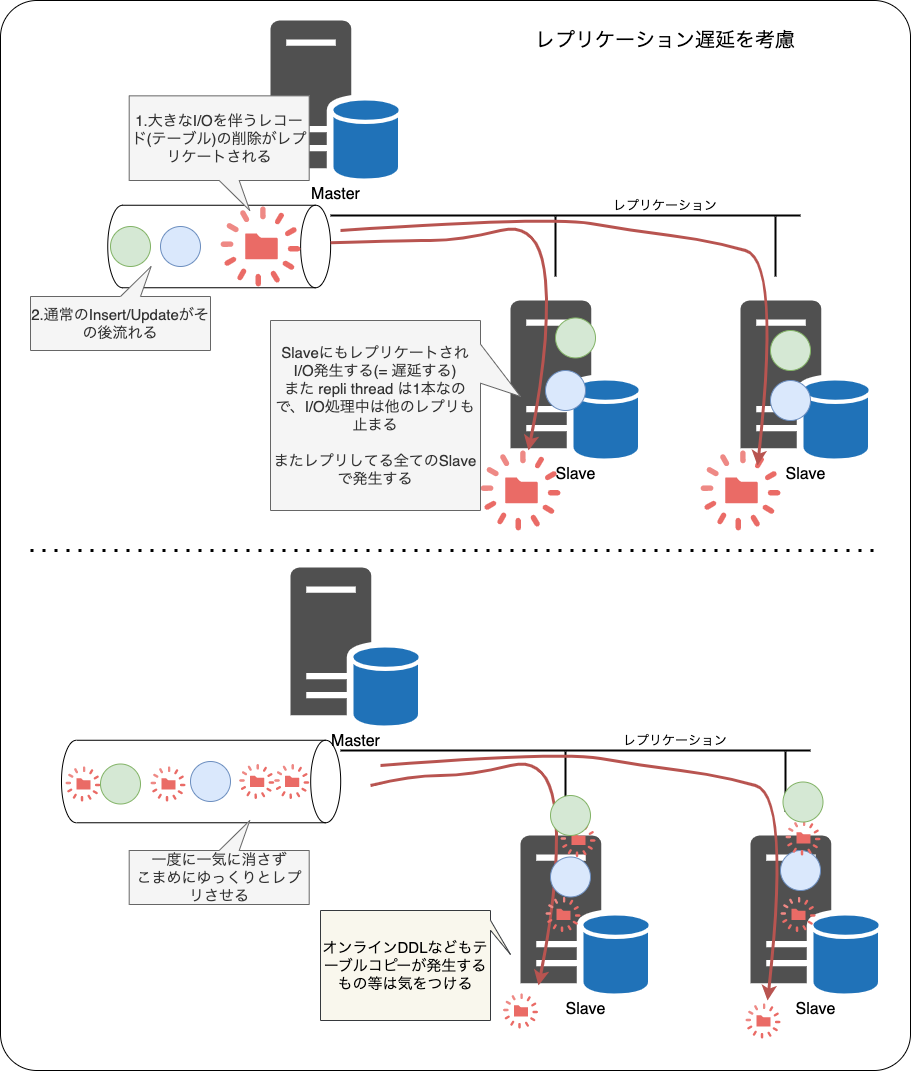
また innodb_file_per_table 構成で運用している場合でも単一のテーブルの断片化/肥大化したものは小さくならないため、OS側の領域を小さくするために ALTER TABLE や OPTIMIZE TABLE する必要があり、それなりに運用の手間が増えます。
MySQLのPartitionを使用した DROP PARTITION はこれら問題を解決できる手段の一つだとは思いますが、プルーニングを意識したクエリをちゃんと実装できないと運用上厳しいものがあるのですが、開発中にはなかなか気が付きにくい のもあり使わなくしていきました
紆余曲折を経て、過去に CREATE TABLE DATA DIRECTORY + DISK Attach という運用も行っていました
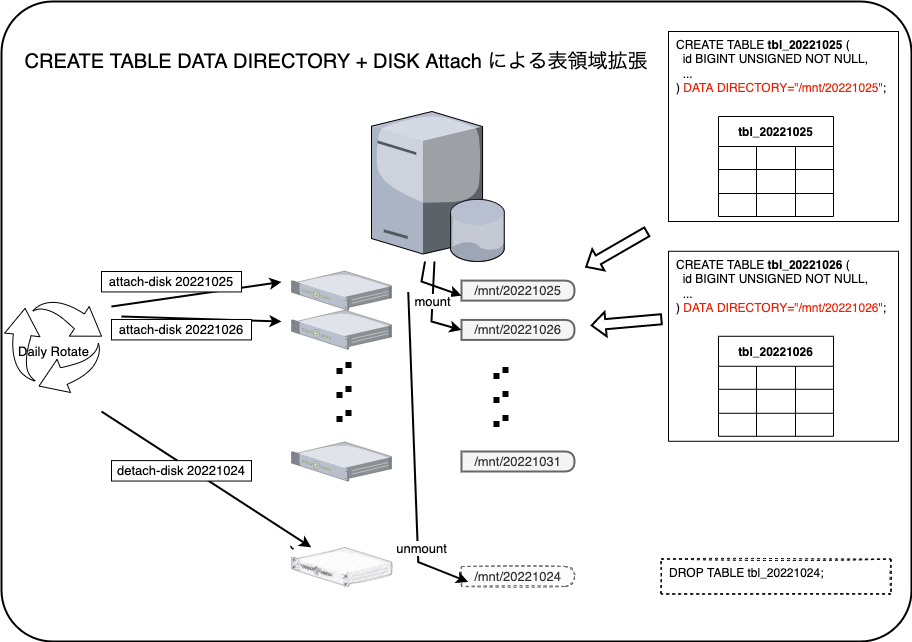
これは、 CREATE TABLE 時に予め指定した ディレクトリに対して表領域を作成するようにするオプションで、VMインスタンスには日時で 追加 Disk を アタッチして必要な領域を確保する方式です
つまり MySQL の VMインスタンスに /volume/yyyymmdd という Disk をアタッチし、テーブル作成時に CREATE TABLE rankingA (...) とするところを CREATE TABLE rankingA_yyyymmdd (...) DATA DIRECTORY='/volume/yyyymmdd' のように指定し、クエリには テーブル+日付 を参照するようにしていました
この実装では、IO性能やDisk容量が別Disk管理となり最適化が行いやすいこと、またパーティションのプルーニングを意識せずとも単一のテーブルを参照することになるのでクエリ・インデックスがシンプルになりやすいです
ただ、こうしてしっかり作り込んでいても、リアルタイム性を求める場面には向いていないのでもうひと工夫必要そうです
候補
これらの課題を解決するソリューションはいくつか存在すると思うのですが、ある程度運用のノウハウを持っていた Redis を検討していました
運用の手間や可用性の高さなどから Redis Cluster と Dynomite を候補にして検証を進めていました
これから紹介するヨシアシのところは検証を進めていた当時の時点での振り返りになるため、時間軸で行くと2-3年前にぶつかっていた壁です(後述)
現時点ではある程度解消されているかもしれません
また、GCPで利用可能な Memorystore for Redis もありましたが、初導入するミドルウェアに関しては細かなロギングを行い、問題が起きた際の早期発見を行いたかった事やメンテナンスの存在 があり見送っています
Redis Cluster のヨシアシ: slot 管理

Redis Clusterは既に導入されている企業も多いと思いますし、選ばれる理由も各社それぞれだと思いますが、僕らは Redis Cluster の全ての機能を使うわけではない(例えばPub/Subなどは別の専用ミドルウェアを利用している)ため、主に機能的なところではなく管理面についてヨシアシの判断をしました
特に運用を行っている場合に必ず起こるイベントといえばメンテナンスです
Redis が乗っているマシンを安全にサービスアウトさせるために、Redis Clusterでは slot の移動を行う必要があります
reshard を行いデータの移し替えをして、データを空っぽにしてノードを削除することでクラスタから参照されなくなるため、このタイミングでメンテナンスを実施します
sharding のスケールアウト/スケールイン を行う際にも reshard を行うことになるのですが、細かな作業ができる反面、運用のひと手間が増えてしまうことから多少ケアする必要があります
また、 Mirrativでは KVのデータ構造であれば memcached で実現していますし、Pub/Sub は既に別のものを利用しています
では Redis の何が使いたいかというと、KV以外のデータ構造(List, Hash, SET...)が永続化されているものを使いたいという事になりました
データが永続化されているとはいえ、MySQLのようにトランザクションを持つものではないため、棲み分けが悩ましいものです(MySQLで頑張るのもまた悩ましいですし)
Dynomite のヨシアシ: sharding/replication

dynomite の良いところは、DC/Rack 単位での分散を考慮したアーキテクチャでしょうか
sharding においてもクライアント側で特別な考慮することなくデータ分散され、dynomite自体が必要なクラスタにレプリケートしてくれるのも良いところです
また 使えるデータ型には制限があります が凝った事をやろうとしなければ十分かなといった印象です
自動化において必要な、クラスタのノードを管理するために必要な membershipのAPI や 状態管理のAPI も用意されているため、内製の管理ツールと連携するのも比較的容易であることも良いところです
例えば Floria API は非常にシンプルな HTTP で通信してくれるので、実装例として hashicorp/memberlist と組み合わせて node管理の動的な変更も行えるような実装を書いてみたりしました。
内製ツールとの連携は、memberlist のところを consul なりに置き換えていくことで管理がしやすくなると思います
クラスタ/ノードの管理方法やアーキテクチャなど個人的には割と好きな dynomite なのですが、課題がいくつか残ります
shardingを拡張する際(逆のshrinkも)の token 管理は、Redis Clusterよりも面倒です
slot 管理のようにデータの移行が行われるわけではないので、適切に key を移動させなければ容量を消費したままになります、そのため Dynomite-manager のようなものや key と token を管理する何かが必要となり管理するものが増えます
その他に dynomite 自体の学習コストが多少なりともあるという点でしょうか、各種ツールが組み込みやすいと多少手を出しやすいのですが色々なものが組み合わさっているのでちゃんと管理できるようになるため訓練が必要です
radisha = Raft + Redis + HA
前置きが長くなりましたが、Mirrativでは radisha という内製の Redis プロトコル互換の Raft クラスタなサーバを開発・運用しています
この radisha ですが、元となっているのは uhaha というフレームワークです
uhaha は、とてもシンプルなフレームワークを提供していて、RESP に相当する部分は隠蔽されており、コマンド部分を実装するだけで Redis コマンドとして利用できます
package main import "github.com/tidwall/uhaha" func main() { conf := uhaha.Config{ Name: "test", InitialData: make(map[string]string), } conf.AddWriteCommand("FOO", cmdFOO) conf.AddReadCommand("BAR", cmdBAR) uhaha.Main(conf) } func cmdFOO(m uhaha.Machine, args []string) (interface{}, error) { key, value := args[1], args[2] data := m.Data().(map[string]string) data[key] = value return "foo", nil } func cmdBAR(m uhaha.Machine, args []string) (interface{}, error) { key := args[1] data := m.Data().(map[string]string) return data[key], nil }
と実装することで
$ redis-cli -p 11001 127.0.0.1:11001> foo test 123 "foo" 127.0.0.1:11001> bar test "123" 127.0.0.1:11001>
このように、Redis のように振る舞いながらコマンドを実装できます
Mirrativ では、uhaha そのものには無い機能をいくつか実装し運用しています
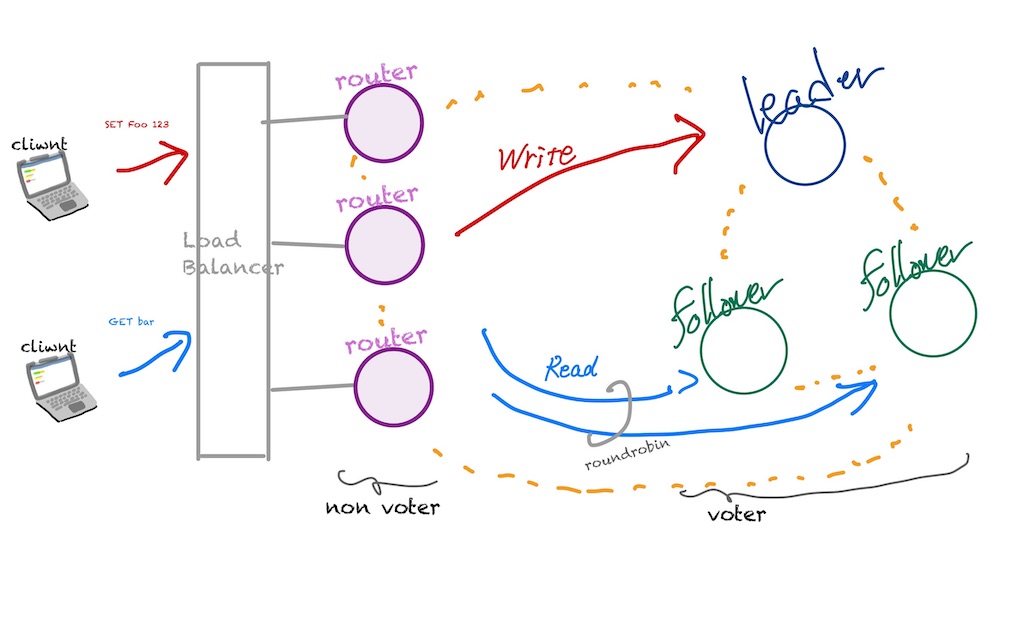
例えば、追加した大きな機能としては、Raft クラスタ内の Leader/Follower ノードを区別し、書き込みコマンド/読み込みコマンドを振り分け(負荷分散機能)る router という仕組みです
router は負荷分散機能だけではなく、 Failover 発生時の Leader の昇格(切り替え)を内部で行うようにしており、クライアント側では特に気にすることなく同じ接続先でありながら処理を継続できるような機能を持っていたり、
レプリケーション遅延を考慮した振り分け処理などを行うようにしたり、アプリケーション側で考慮すべきことをなるべく減らすように実装しています
他にも Redis 運用をしていると、必要となる Key の読み書き頻度の統計データの出力や、クラスタ内の不安定なノードの自動排出などなど、運用上の手間が少なくなるような実装を追加しています
Raft クラスタ
uhahaでの Raftの実装は hashicorp/raft が使われていて、とても使いやすいライブラリです
上記に書いた router の機能は、NonVoter でクラスタ内の状態を監視することで、 Leader / Follower を区別しながら Redis コマンドを振り分けるように実装しています
他にも、Voter で参加しているノードのうち Leader に選出されたノードは、一定期間応答がない(or 不安定な) ノードを検出したらクラスタから外すように実装しており、Observer から、必要な項目を取り出し ながら RemoveServer させたり...
func (s *Server) serverEject(ctx context.Context, ra *raft.Raft) { raftObservationCh := make(chan raft.Observation) go s.readLoop(ctx, ra, raftObservationCh) ob := raft.NewObserver(raftObservationCh, false, func(o *raft.Observation) bool { if _, ok := o.Data.(raft.FailedHeartbeatObservation); ok { return true } if _, ok := o.Data.(raft.ResumedHeartbeatObservation); ok { return true } return false }) ra.RegisterObserver(ob) } func (s *Server) readLoop(ctx context.Context, ra *raft.Raft, ch raft.Observation) { for { select { case <-ctx.Done(): return case ob := <-ch: if ra.State() != raft.Leader { // Leader 以外は特に何もしない continue } switch v := o.Data.(type) { case raft.FailedHeartbeatObservation: count, ok := s.failureHb[v.PeerID] if ok { s.failureHb[v.PeerID] = count + 1 } else { s.failureHb[v.PeerID] = 1 } if threshold < count { // フラッピングしてないかの判定をしつつ // しきい値を超えるものはクラスタから外していく f := ra.RemoveServer(v.PeerID, 0, 0) if err := f.Error(); err != nil { log.Print(err) } delete(s.failureHb, v.PeerID) } case raft.ResumedHeartbeatObservation: delete(s.failureHb, v.PeerID) } } } }
特定のシグナルを受け取ったら LeadershipTransfer しながら、RemoveServerしてクラスタから外れるように実装したり...
func (s *Server) serverShutdownSignal(parent context.Context, signals []os.Signal, ra *raft.Raft) err { ctx, cancel := signal.NotifyContext(parent, signals...) defer cancel() <-ctx.Done() // wait if ra.State() != raft.Leader { // Leader 以外は Leader に対して自分の ServerID を外してもらうよう送信 return requestRemoveServer(ra.Leader(), s.ServerID, 0, timeout) } // Leader であれば移譲してから、クラスタから外してもらうように送信 f := ra.LeadershipTransfer() if err := f.Error(); err != nil { return err } return requestRemoveServer(ra.Leader(), s.ServerID, 0, timeout) }
などなど、実運用をする上で手間がなるべく少なくなるような実装を加えています
また LeadershipTransfer() だけを行うシグナルも用意しているので、例えば メンテナンスイベント を検知したら Leader を転送する、なども実装できるようになっています
コマンドとデータストア
Redis コマンドを自由に作れるということで、Redis の sorted set による同一スコア問題を対処したランキング構造 + コマンドを実装しています
Mirrativではもろもろの実装が楽になるように RANKSET/RANKRANGE のようなコマンドを用意しています
### RANKSET {GROUP} {SCORE} {ID}
radisha-router:6379> RANKSET test-ranking 100 UserHoge
"OK"
radisha-router:6379> RANKSET test-ranking 50 UserFoo
"OK"
radisha-router:6379> RANKSET test-ranking 150 UserFuga
"OK"
radisha-router:6379> RANKSET test-ranking 50 UserBar # UserFoo と同じスコア
"OK"
### RANKRANGE {GROUP} {START} {END}
radisha-router:6379> RANKRANGE test-ranking 0 3
1) 1) "0" # 順位(0始まり)
2) "150" # スコア
3) "UserFuga" # ID
2) 1) "1"
2) "100"
3) "UserHoge"
3) 1) "2"
2) "50"
3) "UserFoo"
4) 1) "3"
2) "50"
3) "UserBar"
RANK データセットは {ID} の辞書順で並び替えているわけではなく、データ挿入時にソート可能となるデータ構造を持つことで同一スコアのランキングでも一意となるようにしています
データストアはこれらコマンドに対応して必要なデータ構造で保存するようにしています(RANKSETの中身は skiplist です)
また Redis にないデータ構造としては TIMESPAN 型(と名付けています)なども持っています
これは一定時間だけデータを溜めておくデータ構造で、僕らは API サーバが出力する HTTP Status コードを保存するようにして、監視用途で使ったりしています
### TSSETEX {KEY} {FIELD} {TTL} {VALUE}
radisha-router:6379> TSSETEX http.status.404 nodeA 60 100 # e.g. 10秒ごとに送る
OK
radisha-router:6379> TSSETEX http.status.404 nodeA 60 100
OK
radisha-router:6379> TSSETEX http.status.404 nodeA 60 100
OK
radisha-router:6379> TSSETEX http.status.404 nodeA 60 100
OK
radisha-router:6379> TSSETEX http.status.404 nodeA 60 100
OK
radisha-router:6379> TSSETEX http.status.404 nodeA 60 100
OK
# この瞬間での集計結果
radisha-router:6379> TSGET http.status.404 nodeA
(integer) 600
# 10秒後に取得すると、最初に送った 100 がexpireされて 500 が返る
radisha-router:6379> TSGET http.status.404 nodeA
(integer) 500
MySQL では実現できそうでも、ちょっとひと工夫が必要そうなデータ構造もある程度自由に(シリアライズ可能である必要はあります)用意していて
オンメモリDBとして動作し、なるべく運用上・またはアプリケーションの実装上の手間が増えないように実装しています
また Redisで利用できる全てのデータ型を使うわけではないので、必要なデータ型だけを実装していて、例えば SET/GET などの KV にあたるものも用意していたりしますが、LISTやSET のコマンドは実装してないので、アプリケーションの開発チームと連携しながら必要なデータ型を実装するようにしています
# KV radisha-router:6379> SET hoge 123 "OK" radisha-router:6379> GET hoge "123" # Hash radisha-router:6379> HSET hoge foo 123 "OK" radisha-router:6379> HSET hoge bar 456 "OK" radisha-router:6379> HGETALL hoge 1) "foo" 2) "123" 3) "bar" 4) "456" radisha-router:6379> SADD myset "foo" "bar" (error) ERR unknown command 'sadd' radisha-router:6379> LPUSH mylist "hello" "world" (error) ERR unknown command 'lpush' radisha-router:6379> RPUSH mylist "hello" "world" (error) ERR unknown command 'rpush'
レプリケーション遅延の考慮
負荷分散のために Follower ノードからデータを読み取りする際には、どうしてもレプリケーション遅延を考慮しながら実装しなければなりません
radisha ではコマンドの先頭に特定の文字列(@)を付与することで、Followerから読み取りを行わず、直接Leaderから読み取りを行うように実装しています
radisha-router:6379> SET hoge 12345 radisha-router:6379> SET hoge 123 radisha-router:6379> GET hoge # 通常は Follower から読み取り radisha-router:6379> @GET hoge # @を付けることで Leader から読み取り
同様に、クラスタに組み込まれたばかりのノードも初回のRaft Log受信中は、データが不完全であるため radisha の router では log の読み取り状況を見ながら振り分け対象から外す等の実装を行って、データを安全に操作できるように組み込んでいます
現在運用中
現在 MySQL で運用していたデータ構造を radisha に移設している最中です
またシステム的なデータは consul kv から radisha に移設し、安定運用できる状態になりました
インフラエンジニアはもちろんバックエンドエンジニアの運用の手間が少なくなるように作っている radisha ですが、課題もいくつか見えてきています
- 大量の(数百万レコード)keyを持つシリアライゼーション
- snapshot 生成時に時間がかかってしまう(raft logのcompactionで使用する)
- sharding の実装
- read の分散はできるので write の分散を行う用途
- 容量のスケールをしやすく
などなど、まだまだ大規模運用に向けて解決していく課題はあり絶賛開発中です!
We are hiring!
インフラエンジニアもバックエンドエンジニアも運用が楽になるように、ひと工夫を一緒に開発してくれるエンジニアを募集しています!