こんにちは、テックリードの夏です。
今年4月にCTOからテックリードに肩書が変わり、ガリガリコードを書くようになりました。 背景については、こちらをご覧ください。
普段はプロダクト側の機能開発と、サーバ側の基盤開発を半々ぐらいの割合で仕事しています。 一口にサーバ側の基盤開発といっても定義が曖昧なのですが、基本的にはこんな感じのタスクをやっています。
- インフラコストの最適化
- 不正なアクセスからの防御
- 障害の再発防止
- 新技術の導入やアーキテクチャの整備
今回はこのうち「新技術の導入やアーキテクチャの整備」の中で、サーバサイドをGo + Clean Architectureで再設計したことについてお話したいと思います。
背景
ミラティブは2015年春頃に開発が始まり、同年8月にサービスがリリースされ、2020年8月で5周年を迎えました。 その過程で組織やプロダクトが成長するにつれ、サーバサイドには以下のような負債が溜まっていました。
- アーキテクチャが崩れかけている
- MVC + Serviceだが、依存関係がスパゲッティ
- Service = Controllerの処理を共通化したレイヤー
- 膨れ上がるModel
- データ型 + 永続化の両方を担当
- 場合によってはPresenter的な仕事も
- Contextという名のもとにあらゆるレイヤーから密結合を黙認されているGodなクラス
- MVC + Serviceだが、依存関係がスパゲッティ
- query digestやslow queryなどで危険なSQLが洗い出されても、どこで発行されているのか調査に時間がかかる
- method chainによる柔軟なSQLの組み立てのメリットがもはや負債
- Modelが永続化も内包しているせいで、様々なレイヤーから実行時にSQLが発行される恐れアリ
- 果てはViewからも。。。
- 負債が溜まったテーブルを再設計しづらい
- テストがすべてシナリオテストで書かれている
- テストの実行時間が長い
- シナリオテストは開発者によって書き方に差異が出やすい
- エッジケースのテストを書くためのコストが大きい
また、ミラティブのサーバサイドは開発当時の事情によりPerlで書かれているのですが、OSSコミュニティでのプレゼンス低下なども踏まえてGoへの移行を検討し始めました。
そこで、サービス固有の歴史的経緯やインフラ構成に即したコードを表現できるか確認するために、Go言語とアーキテクチャの整備を同時に行うのではなく、 既存のPerl側のコードで上記の課題を改善し得るアーキテクチャを整備してから、Go移行を進めることになりました。 これにより、標準的なDBの負荷分散手法を抽象化できるか、トランザクションやロギングをどう表現するのか、チームに受け入れられるかどうかなどもGo移行に先んじて検証することができました。
半年くらいかけてPerl側のClean Architectureのプロトタイプを完成させ、1年かけてサーバチーム全体に浸透させました。現時点では、既存アーキテクチャのコードはフリーズしています。 また、Perl側のアーキテクチャ刷新と並走しながら、Goのプロトタイプ実装を進めてきました。
Go移行に関しては正直まだDaemonやBatchなど、移行しやすいコンポーネントしか本番投入出来ていません。しかし、テックブログを書くことで逆説的に社内への普及を加速させるためにも、 ミラティブのサーバサイドのGoコードのアーキテクチャをまとめてみようと思います。
Clean Architecture
アーキテクチャを再設計する上でClean Architectureを参考にすることにしました。 世の中のClean Architectureの文献を色々漁ってみても、コアとなる考え方は同じなのですが、細部に関してはいろいろな流派があるように見受けられます。 そこで、Clean Architectureとして正解を追うのではなく、過去の実装上の経緯を背負った上で、辛みポイントを解消できるようなアーキテクチャを設計しました。 Clean Architectureがどういうものなのかは参考記事に譲るとして、本記事ではミラティブで利用されているコードに近い形で、設計の詳細に入りたいと思います。 (本家本元のClean Architectureとは異なる場合がありますが、ご了承ください)
qiita.com qiita.com qiita.com www.m3tech.blog (「なぜ書くのか」に激しく同意)
再設計する上で大事にしたポイントは、「コンポーネントの依存性を一方向にする」の一点に集中するかなと思います。 これはなにも、ミドルウェアを差し替えた場合でも、内側のビジネスレイヤーを1行も変更したくないレベルの抽象化を目指したいわけではなく、 負債が溜まったMySQLのtableを再設計する際の影響範囲を最小限に留めようとか、外側の依存性を内側に注入することで、外部APIに依存する処理をテスト時だけモックを差し込みやすくすることなどが目的です。
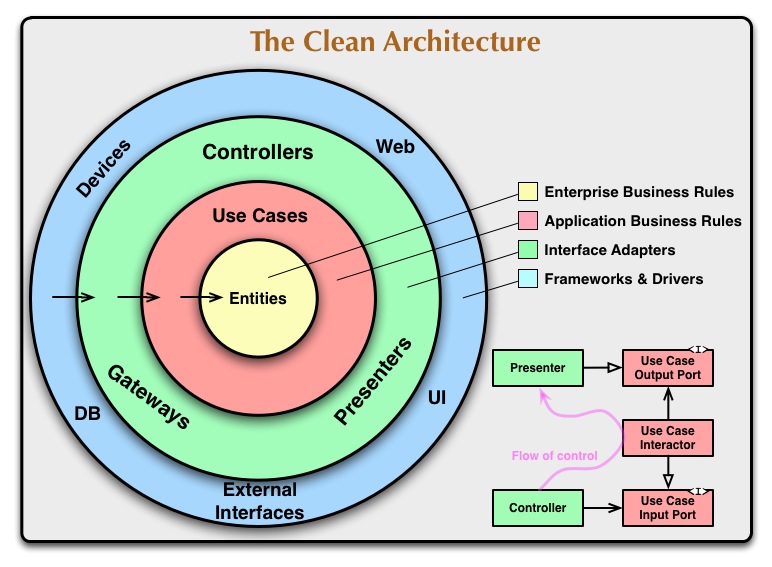
ディレクトリ構造
├── entities ├── usecases │ ├── inputport │ ├── interactor │ │ └── user │ └── repository ├── gateways │ ├── repository │ │ ├── user │ │ └── datasource │ │ ├── dsmemcached │ │ └── dsmysql │ ├── datasource │ │ ├── dsmemcachedimpl │ │ └── dsmysqlimpl │ └── infra │ ├── infradns │ ├── infralogger │ ├── inframemcached │ └── inframysql ├── controllers │ ├── daemon │ └── web ├── frameworks │ ├── daemon │ └── web ├── cmd // アプリケーションの起動コマンドや、各種lint/generator/migrationコマンドが存在 │ └── wire // DIライブラリ google/wire の定義ファイル └── utils // インフラレイヤーにもビジネスレイヤーにも該当しないutility群
Entities
オブジェクトでビジネスロジックを表現する責務を負っています。 ここでいうEntityは、DDDなどでのEntityとは違い、一意な識別子が存在しないものも定義しています。
これにより、Loggerのように全レイヤーから参照されるinterfaceなどもEntitiesに存在しています(実装はInfra層)。
package entity type UserID uint64 type User struct { UserID UserID Name string } type Logger interface { Error(ctx context.Context, err error) Log(ctx context.Context, level LogLevel, label string, payload ...interface{}) }
UseCases
Entity・Repositoryを使い、ユースケースを達成する責務を負っています。
└── usecases ├── inputport │ └── user.go ├── interactor │ └── user │ └── interactor.go └── repository └── user.go
ここでは usecases/inputport ディレクトリにinterfaceを定義し、
package inputport import ( "context" "time" ) type User interface { UpdateRecommend(ctx context.Context, now time.Time) error }
usecases/interactor ディレクトリにその実装を配置しています。
また、トランザクションのスコープを管理するのもInteractorのお仕事です。
package user import ( "context" "time" "server/entities/entity" "server/usecases/inputport" "server/usecases/repository" ) type interactor struct { txm repository.TransactionManager repoUser repository.User } func New(txm repository.TransactionManager, repoUser repository.User) inputport.User { return &interactor{ txm: txm, repoUser: repoUser, } } func (i interactor) UpdateRecommend(ctx context.Context, now time.Time) error { var recommendUserIDs []entity.UserID // おすすめユーザを計算 return i.txm.Do(ctx, func(txns repository.Transactions) error { return i.repoUser.UpdateRecommend(ctx, txns, recommendUserIDs) }) }
usecases/repository ディレクトリにはInteractorが要求するRepositoryのinterfaceが定義されます。
package repository import ( "context" "server/entities/entity" ) type User interface { ReadRecommend(ctx context.Context) ([]entity.User, error) UpdateRecommend(ctx context.Context, txns Transactions, recommendUserIDs []entity.UserID) error }
Repository
データの集約、永続化の責務を負っています。 対応するDataSourceを活用し、UseCasesレイヤーが実際のテーブル構造などを把握しなくてもEntityの永続化を行える責務を負っています。
- データの整合性が取れる最小単位
- 例)MySQL側のDataSourceを更新したら、Memcached側のDataSourceも更新
- DataSourceで取得したデータをEntityに変換
- CRUDなinterfaceを提供
- 命名規則もCreate/Read/Update/Deleteを強制
└── gateways └── repository ├── datasource │ ├── dsmemcached │ │ └── recommend_users.go │ └── dsmysql │ └── user.go ├── transaction │ └── repo.go └── user └── repo.go
usecases/inputport で定義されたRepositoryのinterfaceの実装が配置されています。
package user import ( "context" "server/entities/entity" "server/gateways/repository/datasource/dsmemcached" "server/gateways/repository/datasource/dsmysql" "server/usecases/repository" ) type user struct { dsmemcachedRecommendUsers dsmemcached.RecommendUsers dsmysqlRecommendUser dsmysql.RecommendUser } func New(dsmemcachedRecommendUsers dsmemcached.RecommendUsers, dsmysqlUser dsmysql.User) repository.User { return &user{ dsmemcachedRecommendUsers: dsmemcachedRecommendUsers, dsmysqlRecommendUser: dsmysqlRecommendUser, } } func (r user) ReadRecommend(ctx context.Context) ([]entity.User, error) { // dsmemcachedRecommendUsersからおすすめユーザを取得 // なければdsmysqlUserから問い合わせ // 取得したDataSource固有の構造体をEntityへ変換 } func (r user) UpdateRecommend(ctx context.Context, txns repository.Transactions, recommendUserIDs []entity.UserID) error { // dsmysqlRecommendUserで更新してから、dsmemcachedRecommendUsersを更新 }
gateways/repository 以下には、Repositoryが期待するDataSourceのinterfaceを定義しています。
package dsmysql import ( "context" "server/entities/entity" ) type RecommendUsers interface { Update(ctx context.Context, txns repository.Transactions, users []*RecommendUserRow) error Select(ctx context.Context) ([]*RecommendUserRow, error) }
Transaction
複数のInfra・DataSourceへのトランザクションを管理する責務を追っています。 (トランザクションスコープはInteractorで管理)
ミドルウェアを跨った厳密なトランザクションはサポートされていませんが、複数のMySQLのデータベースへの書き込みがある場合は、 すべての処理が完了してからのcommitやエラー時にすべてのsql.Txのrollbackなどを抽象化しています。
package repository import "context" // commitとrollbackができるものをTransactionと定義 type Transaction interface { Commit(ctx context.Context) error Rollback(ctx context.Context) error } // 複数のTransactionを抽象化し、同一データベースへのTransactionはキャッシュする type Transactions interface { Get(key string, builder func() (Transaction, error)) (Transaction, error) Succeeded(f func() error) // cache更新などrollbackできない(厳密な整合性を担保しなくていい)処理などを登録し、全てのcommitが成功した場合のみ実行する } // トランザクションのスコープを管理するオブジェクト(dry-run時は最後に全てrollbackする) type TransactionManager interface { Do(ctx context.Context, runner func(txns Transactions) error) error }
DataSource
Infraを活用し、Repositoryが要求するデータの取得、永続化を達成する責務を負っています。
- MySQLのtableや、Memcachedのkey、ElasticSearchのtypeと1:1の関係
- 該当するミドルウェア固有の操作名に沿った命名規則
- SQLであればSelect/Insert/Update/Delete
- CacheであればGet/Set
└── gateways └── datasource ├── dsmemcachedimpl │ └── recommend_users.go └── dsmysqlimpl └── recommend_user.go
gateways/repository 以下で定義されたDataSourceのinterfaceの実装が配置されています。
package dsmysqlimpl import ( "context" "server/entities/entity" "server/gateways/infra" "server/gateways/repository/datasource/dsmysql" "server/usecases/repository" ) type recommendUser struct { infraMySQL infra.MySQL } func NewRecommendUser(infraMySQL infra.MySQL) dsmysql.RecommendUser { return &recommendUser{infraMySQL: infraMySQL} } func (ds recommendUser) Update(ctx context.Context, txns repository.Transactions, users []*dsmysql.RecommendUserRow) error { txn, err := ds.infraMySQL.GetTxn(ctx, txns, "BASE_W") // BASE_W はデータベース系統の名前 if err != nil { return nil } _, err = txn.ExecContext(ctx, "delete from recommend_user") if err != nil { return err } _, err = txn.ExecContext(ctx, "insert into recommend_user ...") return err } func (ds recommendUser) Select(ctx context.Context) ([]*dsmysql.RecommendUserRow, error) { return SelectRecommendUser(ctx, ds.infraMySQL, repository.DB_R) }
このうち、 dsmysql.RecommendUserRow の構造体や SelectRecommendUser の処理などは、以下のような内製のテーブル定義から自動生成しています
( kyleconroy/sqlc をオマージュしました)
recommend_user: columns: - name: user_id type: uint64 foreign_key: user.user_id - name: name type: string collation: utf8mb4_bin primary_keys: - user_id queries: - sql: select * from recommend_user
このテーブル定義からDDLを生成し、 k0kubun/sqldef に食べさせることで、MySQLのマイグレーションなども行っています。
Infra
ミドルウェアとの実際の接続や入出力などを担当するレイヤーです。 内側のレイヤーが各ミドルウェアのI/Fを把握せずとも利用できる状態にする責務を負っています。
└── gateways └── infra ├── cache.go ├── config.go ├── db.go ├── dns.go ├── infradns │ └── infradnstest ├── infrahttp │ └── infrahttptest ├── infralogger │ └── infraloggertest ├── inframemcached │ └── inframemcachedtest ├── inframemorycache └── inframysql └── inframysqltest
gateways/infra 直下には各種ミドルウェアの入出力のinterfaceが定義しています。
package infra import ( "context" "database/sql" "server/go/usecases/repository" ) type Transaction interface { repository.Transaction DB } type MySQL interface { Get(ctx context.Context, name string) (DB, error) // 複数系統のデータベースが存在するのでnameで指定する GetTxn(ctx context.Context, txns repository.Transactions, name string) (Transaction, error) } type DB interface { ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error) }
そして、実際の実装はさらに一階層掘って定義しています。 そして、さらに一階層掘ったディレクトリにはtest用の実装が存在しています。 (loggerであればファイルに書き出さずに出力内容を変数として保持しておくとか)
Frameworks
外界からの入力をControllerへルーティングする責務を負っています。 ここでは時刻情報も外界の一部としてみなし、このレイヤー以外では現在時刻を取得しないように制限しています。 これにより特別なライブラリを用いずともテストを決定的にしたり、動作確認する際に任意の時刻への変更を行いやすくなります。
- Web
- HTTP RequestのURLなどを参照し、該当するControllerへRequestを渡す
- Sessionの解決などもこのレイヤー
- RequestやResponseがOpenAPIの定義通りかどうかを検証する
- 実行速度が犠牲になるので開発環境のみ
- 内部に引き回す時刻情報はリクエストを受け取った時刻
- HTTP RequestのURLなどを参照し、該当するControllerへRequestを渡す
- Daemon
- queueベースで動作している非同期処理の場合は、該当のqueueからdequeue処理とControllerをつなげる
- 内部に引き回す時刻情報はenqueueされた時刻
- それ以外の非同期処理の場合は、実行間隔だけが指定されるので、指定された頻度でControllerを実行する
- 内部に引き回す時刻情報はControllerが実行された時刻
- queueベースで動作している非同期処理の場合は、該当のqueueからdequeue処理とControllerをつなげる
Controllers
外界からの入力を、達成するユースケースが求めるインタフェースに変換する責務を負っています。 HTTP Request内のパラメータを取り出したり、queueの中から必要な情報を取り出して適切なInteractorに渡したりします。
また、ミラティブではPresenterを呼び出すのはInteractorではなくController内なので、 Interactorから返ってきたEntityをPresenterで変換し、外界が求める出力フォーマットに変更するのもControllerの責務です。
package user import ( "context" "server/controllers/web" "server/presenters/user" "server/usecases/inputport" ) type Controller struct { user inputport.User } func New(user inputport.User) *Controller { return &Controller{user: user} } func (c Controller) RecommendUsers(ctx context.Context, webCtx *web.Context) error { recommendUsers, err := c.user.ReadRecommendUsers(ctx) if err != nil { return err } return webCtx.RenderJSON(ctx, map[string]interface{}{ "users": user.PresentUsers(recommendUsers), }) }
テスト戦略
もともとはすべてシナリオテストでカバーしていたのですが、アーキテクチャを再設計したタイミングで、 基本的なカバレッジ率の達成にはユニットテストを用い、統合テストでは正常系のユースケースのみ検証しています。
(ここに登場する話が身につまされたので、今後はTesting Pyramidに従おうと思います) testing.googleblog.com
テストのカバレッジ率は90%以上を目指しており、それ以下の場合はCIに怒られるように設定しています。
高めの数字を置いてはいますが、実は go tool cover で出力されるカバレッジ率は使っていません。
以下のようなテストを書くコストが見合わなさそうなブロックを除いてカバレッジ率を計算しているので、思ったほど酷な数字ではないと思います。
- errorが存在していたら後続処理を行わずに、呼び出し元にreturnするだけのif文
- panic
- そもそも初期化時やアプリケーション実行中にどう足掻いても復旧できない場合のみpanicを使用しているため
- delegateのように引数を一切加工せずにフィールドに渡すだけの関数
また、テストの実行速度は生産性に直結するため、すべてのテストにt.Parallelを指定することをLintで強制したり、 データベース名にユニークなsuffixを差し込むことでテスト同士で衝突しないようにしたり、Fixtureのロードを該当するtableへのSQLが実行された場合のみ行ったりと、小技を駆使しています。
今後の展望
現在、DaemonやBatchは本番投入済みで、Web側のいくつかエンドポイントもGo実装が完了しています。 しかし、モノリシックなPerlのWebサーバを移行していくのはそう簡単ではなく、 現在インフラチームと協力しながら、前段にProxyを挟みながら、特定のエンドポイントだけGo + Dockerコンテナで受けられるような仕組みを開発中です。
来期中にWebの本番投入と新機能の開発を全てGo化、半年後にはPerlコードのフリーズまでできると最高だなあと妄想しつつ、きっと色々ハマると思いますし、 アーキテクチャの整備に完成などないので、面白いことがあったらまたテックブログネタにしようかなと思います。
We are hiring!
ミラティブでは サービスや組織の成長に合わせて、生産性を最大化するためのより良いアーキテクチャを模索し続けられるサーバエンジニアを募集中です! meetup も開催しているため気軽にご参加ください!