
はじめまして、Azuma(@azuma_alvin)です。現在大学院の1年生で、2024年2月から4ヶ月間ミラティブのインフラチームにインターンとして参加しました。普段はインフラやMLOpsといった領域に興味があり、最近はVim環境の整備がマイブームです。
本記事では、ログ基盤をFluentdからFluent Bitへ部分移行した経緯とその2種類の監視ツールの実装についてお話しします。
記事の最後に、インターンから見たインフラチームの特徴と私が4ヶ月間で学んだことを紹介しています。興味がある方は末尾までスクロールしてぜひご覧ください。
- 1. 背景と目的
- 2. ミラティブのログ基盤について
- 3. ログ欠損の原因調査
- 4. FluentdからFluent Bitへの部分的移行
- 5. Fluent Bit監視ツールの実装
- 6. インターンを振り返って
- 7. まとめ
- We are Hiring!
1. 背景と目的
ミラティブではバックエンドアプリケーションのエラーログを確認するためにSentryというツールを利用しています。
一方で、アプリケーションがローカルに直接出力する生ログもインフラ側で収集しています。目的としては、Sentryを利用できない障害時もエラーを収集することと、CLIによる高速かつ柔軟な集計を可能にすることの2つがあります。この生ログはFluentdを利用してリアルタイムにログ集約サーバーに転送しています。
このようにアプリケーションのエラーログをSentryと生ログという2通り*1の方法で収集していますが、エラー発生時にログ集約サーバー上の生ログの方がSentryよりもエラー件数が少ないケースがありました。
今回のインターンの課題はこのログ欠損の原因調査とログ基盤の改善でした。
タイトルにもあるように、最終的にはログ収集ツールであるFluentdをFluent Bitに移行していますが、その詳細な経緯については後述します。
2. ミラティブのログ基盤について
ここで、ミラティブのログ基盤について簡単に説明させてください。

まず、ミラティブではインスタンスの役割・系統を表す単位をusageと呼んでいます。例えばWebサーバーの処理を行うusageの名前にはweb-という接頭辞が付き、データベースを提供するサーバーにはdb-という接頭辞が付いています。
今回扱うログを管理するサーバーも log- という接頭辞が付き、ログを集約するサーバーを log-aggregate や ログのルーティングをするサーバーを log-routing などと表現しています。
Webサーバーで発生したログは、infra側とanalysis側という2つのパイプラインに分かれて処理されます。
infra側はエラーログとアクセスログを収集する役割を担っています。Webサーバーでエラーログやアクセスログが書き込まれると一度log-routingに転送され、さらにlog-accesslogとlog-aggregateにルーティングされた後、ファイルに書き込まれます。
一方、analysis側はBigQueryに分析ログを挿入する役割を担っています。Webサーバーで分析ログが書き込まれるとlog-commonに転送されてファイルに保存された後、順次BigQueryに挿入されます。Webサーバーのインスタンスからlog-commonを分離しているのは、BigQueryへのログ挿入が遅いことへの対処です。具体的には、頻繁にオートスケールやローリングアップデートを行うWebサーバーでBigQueryへのログ挿入の待ち時間を考慮する必要が出てきて、すぐにサーバーを入れ替えることが難しくなり、コストパフォーマンスが悪いためです。
1章で説明したログ欠損が発生したと考えられるのは、エラーログの収集を行なうinfra側です。つまり、 Webサーバー(送信元)→log-routing(ログの振り分け) →log-aggregate(ログの集約) のいずれかのステップが欠損の原因であると考えました。
3. ログ欠損の原因調査
Fluentdのバッファリングの仕組み
ログ欠損の原因としてよく疑われるのがバッファリングの設定です。
以降、Fluentdのバージョンは明記しない限りミラティブで使用しているv0.12とします。
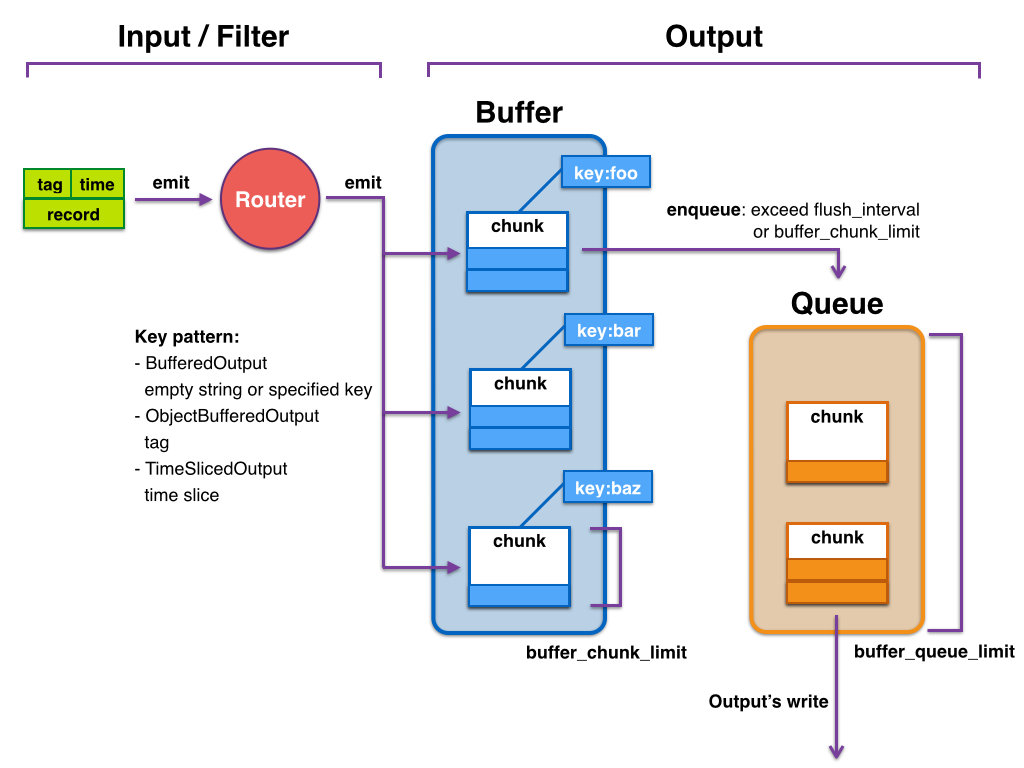
{kind=link}
Fluentdのバッファには、複数のログがまとめられたchunkと呼ばれるものが入っています。図に示されるように、バッファ内のchunkがバッファサイズやインターバルなどの条件によって出力キューにフラッシュされ、目的地に送信される仕組みです。
バッファリング関連のオプションとしてdisable_retry_limit(チャンク送信の最大リトライ回数retry_limitを無効化するかどうか)やretry_wait(exponential backoffアルゴリズムによるリトライ待ち時間のシード値)などがあります。
公式ドキュメントを参照しながらFluentdの設定ファイルのオプションを見直しましたが、既存のログ基盤ではログ欠損を許容するようなバッファリングオプションは設定されていないことが確認できました。
fsnotifyを用いたバッファリングの観察
公式ドキュメントから、バッファリングの大まかな流れは分かりました。
しかし、バッファリングに利用されるファイルのライフサイクルについては把握できていないままでした。もしバッファファイルへの書き出しに欠損の原因があるとすれば、Fluentdによって作成・更新・削除されるファイルの挙動を注意深く観察する必要があります。
Fluentdのbufferプラグインとしてはmemoryとfileの2種類が提供されています。ミラティブでは、バッファ内のチャンクをディスクに保存するfile bufferプラグインを使用しています。
以下の設定は、バッファファイルを/fluentd/data/buffer/ディレクトリに保存しつつ、特定のタグにマッチしてログをファイル(/log/${tag}.YYYYmmdd_HHMM.log)に出力する例です。
<source> @type tail path /log/app/error.log.%Y%m%d_%H%M pos_file /fluentd/data/log/error.log.pos format /^(?<message>.*)$/ read_from_head true tag error.log </source> <match **> @type file path /fluentd/data/test buffer_type file buffer_path /fluentd/data/buffer flush_interval 1s </match>
この例を利用して、Fluentdがどんなファイルをどのタイミングで作成・更新・削除しているのか観察します。
ファイル監視を実現するため、Goでfsnotify/fsnotifyを使用して次のようなコードを書きました。
package main import ( "flag" "fmt" "log" "os" "github.com/fsnotify/fsnotify" ) func main() { var ( out = flag.String("o", "output.log", "output file path") path = flag.String("p", "/var/fluentd", "path to watch") ) flag.Parse() watcher, err := fsnotify.NewWatcher() if err != nil { log.Printf("error: failed to create watcher: error=%+v", err) os.Exit(1) } defer watcher.Close() file, err := os.OpenFile(*out, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644) if err != nil { log.Printf("error: failed to open file: error=%+v", err) os.Exit(1) } defer file.Close() log.SetOutput(file) go func() { for { select { case event, ok := <-watcher.Events: if ok != true { return } switch { case event.Has(fsnotify.Write): log.Printf("info: write: %s", event.Name) case event.Has(fsnotify.Create): log.Printf("info: create: %s", event.Name) case event.Has(fsnotify.Remove): log.Printf("info: remove: %s", event.Name) } case err, ok := <-watcher.Errors: if ok != true { return } log.Printf("error: %+v", err) } } }() if err := watcher.Add(*path); err != nil { panic(err) } <-make(chan struct{}) }
コマンドライン引数のpathにはFluentdのバッファファイル等が格納されるディレクトリ(プログラムを実行するマシンから見たパス)を指定します。
このプログラムを実行した後、Fluentdのtail inputプラグインで指定したディレクトリに別ターミナルから一定間隔でログを書き込んだ結果を以下に示します。
$ go run main.go 2024/03/06 15:14:40 info: create: /var/fluentd/buffer/test.20240306.b612f7dfc410cef08 2024/03/06 15:14:40 info: write: /var/fluentd/buffer/test.20240306.b612f7dfc410cef08 2024/03/06 15:14:40 info: create: /var/fluentd/buffer/test.20240306.q612f7dfc410cef08 2024/03/06 15:14:40 info: create: /var/fluentd/test.20240306_5.log 2024/03/06 15:14:40 info: write: /var/fluentd/test.20240306_5.log 2024/03/06 15:14:40 info: remove: /var/fluentd/buffer/test.20240306.q612f7dfc410cef08 2024/03/06 15:14:41 info: create: /var/fluentd/buffer/test.20240306.b612f7dfd34ac0dc8 2024/03/06 15:14:41 info: write: /var/fluentd/buffer/test.20240306.b612f7dfd34ac0dc8 2024/03/06 15:14:41 info: create: /var/fluentd/buffer/test.20240306.q612f7dfd34ac0dc8 2024/03/06 15:14:41 info: create: /var/fluentd/test.20240306_6.log 2024/03/06 15:14:41 info: write: /var/fluentd/test.20240306_6.log 2024/03/06 15:14:41 info: remove: /var/fluentd/buffer/test.20240306.q612f7dfd34ac0dc8 # 省略
結果から、キューの実態もファイル(test.20240306.q612f7dfc410cef08 など、 yyyymmdd.q*** という命名規則のファイル)であることが分かりました。バッファファイル(test.20240306.b612f7dfc410cef08 など、 yyyymmdd.b*** という命名規則のファイル)は作成されてから削除されるまで時間が空くのに対し、キューファイルは作成後すぐに削除されてしまいます*2。
キューファイルを目視で観察することは難しく公式ドキュメントにも記載がないため、Fluentd自体のソースコードを読むか、fsnotify(もしくはinotifyの類)を使用して観察しないと分からなかったと思います。
さて、バッファリングによってバッファファイルとキューファイルが作成・更新・削除されるタイミングを観察できました。 どちらもファイルへの書き込み処理が行われるため、次はこれらのファイルに書き込まれるログ数が元のログ数に一致するかどうかを観察すれば良いと考えました。
負荷試験
負荷試験の目的は、実際にログ欠損が起きたproduction環境のWebサーバーと同等のスピードでログを書き込み、欠損あるいは遅延の発生条件を発見することです。
送信元であるWebサーバーのインスタンスを想定して、tail inputプラグインの監視対象パスにCLIツールでログを書き込み、forward outputプラグインでlog-routingに転送する試験を行いました。実際の送信元がWebサーバーの処理を行うことも考慮して、CPU使用率を上げた負荷試験も行いました。
以下の表に結果を示します。
| インターバル [s] | CPU負荷 | ログ損失 | ログ遅延 [s] |
|---|---|---|---|
| 1 | 0 | 0 | |
| 1 | ✔️ | 0 | 0 |
| 0.1 | 0 | 1 | |
| 0.1 | ✔️ | 0 | 5 |
| 0.01 | 0 | 1 | |
| 0.01 | ✔️ | 0 | 14 |
| 0.001 | 0 | 7 | |
| 0.001 | ✔️ | 0 | 8 |
CPU負荷の列に✔️が付いている行は、Fluentdとは別のコンテナでyes > /dev/nullを実行し、CPU使用率を100%近くまで上昇させた条件です。これは仮想的にWebサーバの処理負荷が高くなっている状態を作り出すことが目的で、Fluentdが読み込むログの欠損/遅延が発生しやすい状況を作っています。
ログ遅延が1秒単位なのは、送信側でインターバルごとにログ出力するCLIツールの終了タイムスタンプと、受信側でwatchコマンドを使用して1秒ごとに集計を取ったタイムスタンプを比較しているためです。
結果として、CPU使用率を上昇させた場合もログ欠損はゼロでした。
ログ遅延については、CPU負荷をかけた場合に大きくなっていますが、iostatを確認したところ%iowaitがかなり高くなっていたため、これはディスクへの書き出しのレイテンシによって遅延が生じていると考えました。以下はCLIツールでログを書き込む途中のiostatの結果です。
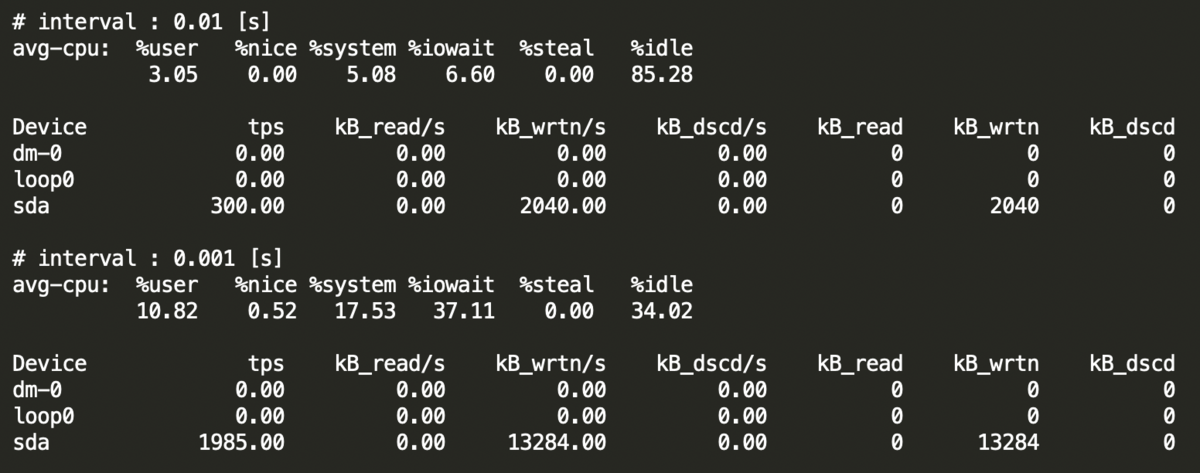
メンターさんに調査していただいたところ、アクセスが増加する時間帯のproduction環境でもログの出力頻度はここまで高く出ていないそうなので、現実に近い負荷の設定でも欠損は起きにくいと考えました。
したがって、この負荷試験によってログ欠損の原因は発見することができませんでした。
もしインターバルを短くした場合にログ欠損が見られれば、先述したようなバッファファイルやキューファイルを監視して、バッファリングのどのタイミングで欠損が起きるのかを掘り下げていく予定でした。
日付時刻フォーマットとワイルドカードによるログ欠損
バッファリングによってログ欠損が発生する可能性は低いことが分かりました。
他にも様々な条件で検証を行い、最終的にはtail inputプラグインのpathパラメータを以下のように設定した場合に欠損を再現することができました。
<source> @type tail path /var/log/app/*/error.log.%Y%m%d_%H%M pos_file /fluentd/data/log/all.error.log.pos format /^(?<message>.*)$/ read_from_head true tag error.log </source>
このpathパラメータの設定はログ欠損が発生していたインスタンスで共通するものでした。具体的な条件は以下の2つです。
- ワイルドカード(
*)の使用 - 日付時刻フォーマット(
%Y,%m,%d,%H,%M,%Sなど)の使用
まず、tail inputプラグインについて簡単に説明します。
tail inputプラグインはtail -Fコマンドと似た挙動をとります。pathパラメータで指定したパスのファイルが読み取られますが、ワイルドカードや日付時刻フォーマットを使用してpath /var/log/app/*/error.log.%Y%m%d_%H%Mのように動的に監視対象のファイルを追加することもできます。
そして、監視対象のファイルリストの更新頻度はrefresh_intervalというパラメータ(デフォルトは60秒)によって指定することができます。
次に、具体例を通してログ欠損が起きる場合と起きない場合を説明します。
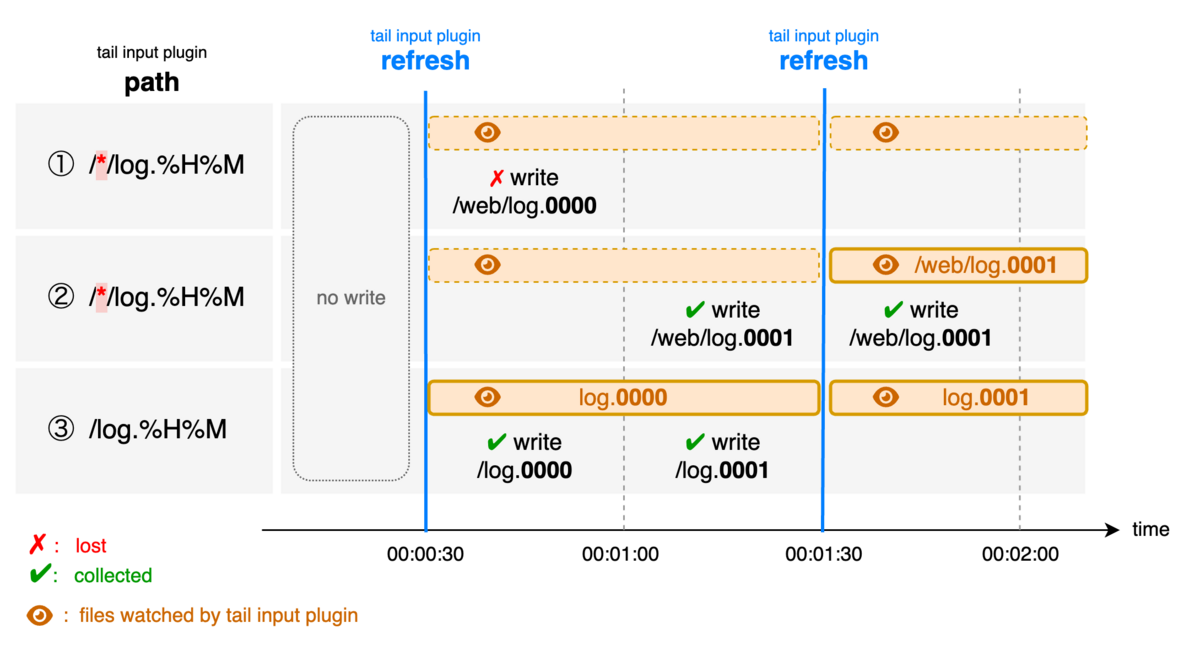
ここではrefresh_intervalはデフォルトの60秒とし、Fluentdの起動タイミングによって毎分30秒に監視対象がリフレッシュされるとします。
ワイルドカードを使用した①の場合、時刻00:00:30にFluentdが監視対象のリフレッシュを行いますが、この時点では指定した/*/log.0000に読み込み可能なファイルが無いため追加する監視対象ファイルはありません。時刻00:00:45にはWebサーバーから/web/log.0000にログが書き込まれます。しかし、このファイルは監視対象となっていないため読み込まれません。次は時刻00:01:30にFluentdは再び監視対象のリフレッシュを行いますが、/*/log.0001にマッチするファイルは存在しないため監視対象ファイルは変化しません。この場合、/web/log.0000に書き込まれたWebサーバーのログは欠損します。
同じくワイルドカードを使用した②の場合、①と同じように時刻00:00:30に監視対象のリフレッシュを行いますが、監視対象ファイルは無いままです。時刻00:01:15にはWebサーバーから/web/log.0001にログが書き込まれます。次に時刻00:01:30にはFluentdが再び監視対象のリフレッシュを行い、/*/log.0001にマッチするファイル/web/log.0001を監視対象に追加します*3。また、時刻00:01:30~00:01:59の間に書き込まれたログも、既に監視対象に追加された/web/log.0001に書き込まれるため、Fluentdによって処理されます。この場合、/web/log.0001に書き込まれたログは欠損しません。
最後にワイルドカードを使用しない③の場合、①や②と同じように時刻00:00:30に監視対象のリフレッシュを行いますが、ファイルの有無に関わらずパス/log.0000が監視対象ファイルに追加されます。これにより、欠損が起きた①と同じタイミング(時刻00:00:45)にWebサーバーからログが書き込まれても、Fluentdの監視対象ファイルであるためログは処理され欠損は発生しません。
これらの例で挙動の違いを生んだ原因は、設定のpathパラメータにおけるワイルドカードの有無でした。
Fluentd v0.12のソースコードを確認すると、以下のようにワイルドカードを使用する場合と使用しない場合で、指定パスのファイルが無い時の監視対象ファイルへの追加条件が異なります。
fluentd/lib/fluent/plugin/in_tail.rb at v0.12 · fluent/fluentd · GitHub
if path.include?('*') # 著者コメント: Dir.glob(path)が実行されるタイミングで存在しないファイルは監視対象外 paths += Dir.glob(path).select { |p| is_file = !File.directory?(p) if File.readable?(p) && is_file if @limit_recently_modified && File.mtime(p) < (date - @limit_recently_modified) false else true end else if is_file unless @ignore_list.include?(path) log.warn "#{p} unreadable. It is excluded and would be examined next time." @ignore_list << path if @ignore_repeated_permission_error end end false end } else # When file is not created yet, Dir.glob returns an empty array. So just add when path is static. paths << path end
ワイルドカードを使用せず静的にパスが決まる場合は、指定したファイルの有無に関わらず監視対象に追加するということがソースコードから読み取れました。これは公式ドキュメントのpathオプションの説明からは読み取れなかったことです。
ミラティブのログ基盤では、usageによってワイルドカードを使用する設定と使用しない設定があります。ログ欠損が発生したインスタンスではワイルドカードを使用しており、またバッファリングの負荷試験はワイルドカードを使用しない設定であったため当初は再現が困難でした。
refresh_intervalを指定せず毎分 秒にリフレッシュされる場合、毎分
個のログがランダムに発生するWebサーバーでは、
の確率でログ欠損が発生することになります。ミラティブで欠損があったのはエラーログであったため、件数が少なくこの確率が高くなっていたことが予想されます。
日付時刻フォーマットとワイルドカードを併用する場合の対策としてrefresh_intervalを短くすることが考えられますが、頻繁にリフレッシュしてもログが欠損する可能性はゼロにはならないため回避すべきです。
代替策として、日付時刻フォーマットを使用せずにワイルドカードのみによってマッチさせる方法があります。この場合、limit_recently_modified パラメータ をセットで指定して、更新されていないファイルを監視対象から外すのもあると良さそうです。
また4章でFluentdの移行先として紹介するFluent Bitは、tail inputプラグインのパスに日付時刻フォーマットを使用できないことと、日付時刻フォーマットを伴わないワイルドカード指定 *では欠損が発生しないことから、今回のログ欠損の解決策として利用することにしています。
ログ保存とサーバータイムスタンプのパース
ログ欠損の原因を調査する過程で、log-aggregateインスタンスにおいてログが正しい日付ディレクトリ内のファイルに出力されない問題も確認しました。
背景から説明すると、ミラティブでは2020年頃からサーバーサイドの技術をPerlからGoに移行する取り組みを行なっており、現在PerlとGoという2つの環境を同時に運用しています。
PerlのWebサーバーとGoのWebサーバーからは異なるフォーマットのログが書き出されます。既存のログ基盤では、ログはパースせず新たにホスト名などのフィールドを付与して、集約側のlog-aggregateで新たに付与したタイムスタンプを基に日付ごとのディレクトリに保存していました。
送信元であるWebサーバーのインスタンスからlog-aggregateインスタンスに到着するまで(flushインターバルを考慮して)3秒かかるとすると、日付が変わる直前3秒間のログは翌日の日付のディレクトリにファイル出力されることになります。ログが急激に増加するタイミングと重なった場合、この影響はさらに大きくなることが予想されます。
この現象が原因でログが欠損する訳ではありませんが、エラーログやアクセスログが急激に増加した場合に、エンジニアが想定したディレクトリと異なるディレクトリに対象のログが存在するのはエラー対応時の障害となりそうです。
対応としては以下の2つが考えられます。
- ログの出力フォーマットを全てPerlとGoで揃える
- ログの送信元または集約先で、PerlとGoのフォーマットそれぞれに対応するパーサーを用意する
1.についてはエラーログの出力箇所がコードベースに点在しているため、相当大きな作業コストがかかってしまいます。
2.については正規表現を使用してFluentdのパーサーを書けそうなので実際に手を動かしてみました。予想に反して、標準プラグインで複雑な正規表現を書くよりもRubyでカスタムプラグインを実装する方がテスト容易性と運用・保守の観点から優れていると感じました。また、既存のlog-aggregateの設定ファイルの大部分を書き換える必要があることが予想されました。
どちらも相応の作業コストが見込まれますが、この課題の対応については、4章の中で改めて説明します。
4. FluentdからFluent Bitへの部分的移行
Fluent Bit移行の経緯
3章の原因調査も踏まえ、ログ基盤のinfra側をFluent Bitに移行することを決定した理由は以下の2つです。
- 現在使用しているFluentdのバージョンが古い
- Fluent Bitの方がFluentdよりもメモリ使用量が小さい
1.について、Fluentdの最新バージョンはv1.x (この記事の執筆時点ではv1.17が最新) ですが、ミラティブで使用しているのはv0.12であり、古いバージョンを使い続けてきたようです。
2.については、公式ドキュメントでFluent Bitのメモリ使用量がFluentdの 以下であると言及されています。
インフラチームでは既にログ基盤のFluentdをv1にアップグレードしたいと考えていました。そのままFluentdの設定ファイルをv1に書き換えることも可能ですが、v0.12↔️v1間でのプラグインの違いや設定ファイルの構文の違いにより修正コストは相当大きくなると見込まれました。3章で述べた、サーバータイムスタンプをパースするための修正コストも決して小さいものではありません。
まずは既存の設定ファイルをFluent Bitで書き換える実現可能性を検証しました。それから、Fluentdをv1に書き換えるコストとFluent Bitに書き換えるコストを比較したうえで、ログ基盤のinfra側を軽量なFluent Bitに移行することにしました。
FluentdとFluent Bitの比較
まず設定ファイルの違いを紹介します。ここでは、Input → Filter → Outputというシンプルな例を用いて比較を行います。
Fluentd(v0.12であることに注意)の設定ファイルを以下に示します。
<source>
@type monitor_agent
bind 0.0.0.0
port 24220
</source>
<source>
@type forward
port 24224
</source>
<filter **>
@type record_modifier
<record>
hostname ${hostname}
</record>
</filter>
<match **>
@type file
path /var/log/fluentd/output.log
buffer_type file
buffer_path /var/log/fluent/myapp.*.buffer
flush_interval 1s
</match>
次はFluent Bitの設定ファイルです。
[SERVICE]
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_PORT 24220
storage.path /var/log/flb-storage/
flush 1
[INPUT]
Name forward
Listen 0.0.0.0
Port 24224
storage.type filesystem
[FILTER]
Name modify
Match *
Add hostname ${HOSTNAME}
[OUTPUT]
Name file
Match *
Path /var/log/fluentbit/output.log
FluentdとFluent Bitの間で基本的な設定項目は類似しており、移行の際のハードルは低いと考えられました。
強いて違いを挙げるとすれば、Fluent Bitでは[SERVICE]セクションでバッファやFluent Bit自体のロギング、監視やパーサー、外部プラグインなどグローバルな設定を定義できることです。バッファについてはグローバルな設定の他に、Input / Outputプラグインのオプションとして固有の設定ができるので可読性が高いと感じました。
移行前後の構成の変化
移行前後でログ基盤のinfra側の構成に大きな変更はありません。
既存の基盤でログの振り分け・集約を担うlog-routing / log-aggregateというusageの名前は、Fluent Bitに移行後にlog-routing-2 / log-aggregate-2としました。
3章で言及したサーバータイムスタンプのパースについては、ログの送信元でGoとPerlに対応したパーサーを導入し、サーバーがログを出力した時点でのタイムスタンプをFluent Bitのタイムスタンプとしてセットするように変更しました。
具体的にはparser filterプラグインを使用して以下のような設定を追加しました。
[SERVICE]
parsers_file /fluent-bit/etc/parsers.conf
[FILTER]
name parser
match *
reserve_data True
key_name log
parser go_parser
[FILTER]
name parser
match *
reserve_data True
key_name log
parser perl_parser
Perlのログには正規表現パーサー、GoのログにはLTSVパーサーを以下のように設定します。
# parsers.conf
[PARSER]
Name perl_parser
Format regex
Regex ^(?<time>[^\t]+)
Time_Format %Y-%m-%d %H:%M:%S
Time_Offset +0900
Time_Key time
[PARSER]
Name go_parser
Format ltsv
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
サンプルログをFluent Bitに入力した場合の出力結果の対応を以下に示します。分かりにくいですが、計算するとFluent Bitレコードのタイムスタンプが入力ログのタイムスタンプに一致していることが分かります。
# 入力するPerlのログ
2024-04-12 15:10:59 EXISTS_SESSION UA/Android/Pixel 7 127.0.0.1 at WebApp 144
# 出力
error.log: [[1712902259.000000000, {}], {"message"=>"2024-04-12 15:10:59 EXISTS_SESSION UA/Android/Pixel 7 127.0.0.2 at WebApp 144", "hostname"=>"eb1b64bdb0be"}]
# 入力するGoのログ
time:2024-04-12T15:12:22.801926654+09:00 level:info host:xxxx app:webapp version:v1.2.3 command:web_common label:http_request method:GET uri:http://xxxxxx/path/to/api?param1=value1 status:200 controller:/api/endpoint trace_id:1111-2222-3333-4444
# 出力
error.log: [[1712902342.801926654, {}], {"level"=>"info", "host"=>"xxxx", "app"=>"webapp", "version"=>"v1.2.3", "label"=>"http_request", "method"=>"GET", "uri"=>"http://xxxxxx/path/to/api?param1=value1", "status"=>"200", "controller"=>"/api/endpoint", "trace_id"=>"abcdefg-4321-0000-9999-12345", "message"=>"...", "hostname"=>"eb1b64bdb0be"}]
Fluent Bitレコードのタイムスタンプをログ出力時のタイムスタンプで書き換えることができました。GoのログはLTSVという形式に従っているので、タイムスタンプ以外のフィールドも全てパースされた状態で送信されます。
Fluent Bit監視のために追加した設定もいくつかありますが、詳細は5章で述べます。
5. Fluent Bit監視ツールの実装
ログ基盤のFluent Bit移行には設定ファイルの書き換えだけでなく、Fluent Bit自体の監視も必要です。
Fluent Bitが「正常に動作しているか」、それから「ログを正しく送信しているか」を監視するために2種類のツールを実装しました。

(1) Fluent Bitが提供する監視を利用
この監視の目的は、Fluent Bit のログの詰まりが起きていないかを発見することです。
これはFluent Bitが提供するメトリクスによって実現できそうです
図の(1) check "up" chunks countに監視のイメージを示しています。
既存のログ基盤のFluentdでも、処理能力の指標としてキューの長さをリアルタイムで監視していました。
Fluent Bitにも似たような指標があります。
Fluentdと同じくFluent Bitでもログがまとめられてチャンクと呼ばれますが、バッファリングを行う際、ログが受信速度 > 送信速度になるとバックプレッシャーが発生します。バックプレッシャーとは、ログの取り込みや作成が送信先へのフラッシュよりも速くなりメモリ消費量が大きくなる現象のことです。メモリとファイルシステムを併用するモードであれば、バックプレッシャーが発生した場合もログ損失は起きませんが、storage.max_chunks_upというオプションでメモリのバッファサイズ制限を設けることもできます。最終的にはチャンクがメモリに読み込まれて"up"な状態になります。
Fluent Bit移行後は、/api/v1/storageエンドポイントのchunks.fs_chunks_upというメトリクスが閾値を超えないかを監視することでFluent Bitのバッファリング処理能力の指標とできそうです。
詳細は以下の公式ドキュメントを参考にしてください。
Buffering & Storage | Fluent Bit: Official Manual
Backpressure | Fluent Bit: Official Manual
実装としては、ミラティブにはcronを利用して実行できる監視基盤があるので、その枠組みを利用してGoで監視ツールを実装しました。
具体的な処理としては、各Fluent Bitで公開したHTTPサーバーのメトリクス取得用のエンドポイント(図では:25224/api/v1/storage)に対してリクエストを送信し、得られた"up"なチャンクの数と事前定義した閾値を比較してSlackにアラート通知を行います。
対象usageのインスタンス情報を取得し、並列にHTTPリクエストを送信するシンプルな実装のため、Goコードの紹介は割愛させていただきます。
(2) タイムスタンプの差分と送信元のホスト名を監視
この監視は、実際にログが送信される経路上で遅延が発生していないこと、それから送信されるべきインスタンスからログが送信されていることを確認するために行います。
Fluent Bitの標準メトリクスから各Fluent Bitの状態を監視することはできても、ログが到達するまでに実際どれくらい時間がかかったか、実際にどのインスタンスからログが送信していないかを確認することはできません。
図の(2) check timestamp diff & sender hostnamesに監視のイメージを示しています。
まずアイデアを簡単に紹介します。
まず、Fluent Bitの各ステップでタイムスタンプ付きのログを定期的に生成して通常のログと同じ経路で転送することで、各Fluent Bitが前段から送信されるのにかかった時間を求めることができます。第一にこのタイムスタンプの差分を監視します。
それから、先述した定期的なログにホスト名も付与することで、各Fluent Bitが前段のどのインスタンスからログを受け取ったかを調べることができます。第二にこのホスト名のリストを監視します。
これらの詳細を実装と一緒に説明します。
監視を行うためには、Fluent Bitの設定ファイルに変更を加える必要があります。log-routing-2を例として、まずは変更を加える前の設定ファイルを示します。
[SERVICE]
http_server On
http_listen 0.0.0.0
http_port 25220
health_check On
flush 2
storage.path /fluent-bit/data/routing/buffer/
storage.max_chunks_up 9999999999999
storage.backlog.mem_limit 32M
[INPUT]
name forward
listen 0.0.0.0
port 25224
storage.type filesystem
[OUTPUT]
name forward
match infra.*
host log-aggregate-2.service.consul
port 24224
workers 2
retry_limit no_limits
foward inputプラグインから入力を受け取り、forward outputプラグインによってlog-aggregate-2にログを転送するというシンプルな処理を行なっています。
次に、追加部分ですが大きく以下の2パートに分かれています。
- exec inputプラグインによって定期的に(ここでは1秒間隔で)タイムスタンプとホスト名からなるログを生成する
- lua filterプラグインによって前段から転送された1.のログのタイムスタンプと現在時刻の差分を算出し、ファイルに保存する
例としてlog-routing-2を選んだのは、1.と2.の両方が登場するためです。
まずは1.による設定ファイルの追加部分を紹介します。
[INPUT]
name exec
tag flb_diff_forward_exec.log
command date +%s
interval_sec 1
interval_nsec 0
buf_size 8mb
oneshot false
[FILTER]
name modify
match flb_diff_forward_exec.log
add hostname ${MY_OS_NAME}
copy exec flb_timestamp
次に、2.による追加部分を紹介します。
[FILTER]
name rewrite_tag
match flb_diff.log
rule $hostname .* flb_diff_forward.log true
emitter_name forward_diff_emitter
[FILTER]
name lua
match flb_diff.log
script /fluent-bit/etc/filters.lua
call calculate_timestamp_diff
[FILTER]
name lua
match flb_diff.log
script /fluent-bit/etc/filters.lua
call set_minute_field
[FILTER]
name rewrite_tag
match flb_diff.log
rule $flb_minute ^([0-9]{8}_[0-9]{4})$ $TAG.$0 false
emitter_name minute_emitter
[OUTPUT]
name file
match flb_diff.log.*
path /fluent-bit/data/routing/diff
mkdir True
retry_limit no_limits
format template
template {time} {flb_diff_routing} {hostname}
lua filterプラグインで呼び出されている関数は別ファイルに書かれていいます。
--filters.lua function calculate_timestamp_diff(tag, timestamp, record) new_record = record if record["flb_timestamp"] ~= nil then diff = os.time() - tonumber(record["flb_timestamp"]) new_record["flb_diff_routing"] = diff end return 2, timestamp, new_record end function set_minute_field(tag, timestamp, record) new_record = record new_record["flb_minute"] = os.date("%Y%m%d_%H%M", timestamp) return 2, timestamp, new_record end
set_minute_field関数でタイムスタンプを分までの文字列にフォーマットしているのは、別のツールでファイルローテーションを行うためです。サイドカーのWebサーバーでメトリクスを公開する範囲より前のデータは不要なのでこまめに削除するようにします。
(2)の監視をまとめると、Webサーバー(送信元)とlog-routing-2のそれぞれで通常のログとは別にタイムスタンプとホスト名を付与したログを一定間隔で生成し、log-routing-2 / log-aggregate-2で前段のFluent Bitとの差分を算出します。差分はメトリクスとして軽量なWebサーバーが集計し公開します。
仕上げとして監視側のGoのコードの一部を紹介します。上に書かれている関数が下に書かれている関数を呼び出すような順番で並べているので、処理の雰囲気だけ理解していただけると幸いです。
package check import ( "bytes" "context" "encoding/json" "fmt" "log" "net/http" "os" "strconv" "strings" "time" "github.com/cenkalti/backoff" "github.com/sourcegraph/conc/pool" ) // 省略 func checkFluentBitTimestampDiffTargets(ctx context.Context, opt fluentBitTimestampDiffOpt) ([]string, []string, error) { p := pool.NewWithResults[*fluentBitTimestampInfo]().WithErrors().WithCollectErrored().WithMaxGoroutines(opt.conc).WithContext(ctx) for _, ti := range cfg.Targets { p.Go(getFluentBitTimestampDiffInfo(ctx, ti.TargetUsage)) } results, err := p.Wait() diffInfos := make([]fluentBitTimestampDiffInfo, 0) hostCheckInfos := make([]fluentBitTimestampHostCheckInfo, 0, len(results)) for _, info := range results { diffInfos = append(diffInfos, info.diffInfos...) hostCheckInfos = append(hostCheckInfos, info.hostCheckInfo) } // 結果からSlackに通知するメッセージ本文を作成 } func getFluentBitTimestampDiffInfo(ctx context.Context, targetUsage string) func(context.Context) (*fluentBitTimestampInfo, error) { return func(context.Context) (*fluentBitTimestampInfo, error) { info := fluentBitTimestampInfo{} check := func() error { if i, err = checkFluentBitTimestampDiff(targetUsage); err != nil { return err // retry } else { info = i } return nil } b := backoff.WithContext(backoff.WithMaxRetries(backoff.NewExponentialBackOff(), opt.backoffMaxRetry), ctx) if err := backoff.Retry(check, b); err != nil { return nil, err } return info, nil } } func checkFluentBitTimestampDiff(targetUsage string) (*fluentBitTimestampInfo, error) { // 監視対象usageのインスタンスをリストアップする instances, err := instance.GetInstances(targetUsage) if err != nil { return nil, err } actualHosts := make(map[string]struct{}) info := fluentBitTimestampInfo{ usage: targetUsage, diffInfos: make([]fluentBitTimestampDiffInfo, 0, len(instances)), hostCheckInfo: fluentBitTimestampHostCheckInfo{ checkAt: make([]string, 0, len(instances)), notFoundHostnames: make([]string, 0), }, } for _, inst := range instances { url := fmt.Sprintf("http://%s:13021/metrics", inst.Address) client := &http.Client{} // error処理の記載は省略 req, _ := http.NewRequest("GET", url, nil) resp, _ := client.Do(req) defer resp.Body.Close() r := FluentBitTimestampDiffResponse{} if err := json.NewDecoder(resp.Body).Decode(&r); err != nil { return nil, err } totalWarnCount, totalFatalCount := 0, 0 totalWarnData, totalFatalData := make(map[string]int), make(map[string]int) warnHostnames, fatalHostnames := []string{}, []string{} for hostname, s := range r.HostDiff { warnCount, warnData := s.getInFieldCountMap(t.ThresholdsWarn) if warnCount > 0 { warnHostnames = append(warnHostnames, hostname) } totalWarnCount += warnCount for k, v := range warnData { totalWarnData[k] += v } fatalCount, fatalData := s.getInFieldCountMap(t.ThresholdsFatal) if fatalCount > 0 { fatalHostnames = append(fatalHostnames, hostname) } totalFatalCount += fatalCount for k, v := range fatalData { totalFatalData[k] += v } actualHosts[hostname] = struct{}{} } di := fluentBitTimestampDiffInfo{ name: t.Name, usage: t.Usage, instance: fmt.Sprintf("%s (%s)", inst.InstanceName, inst.Address), isWarn: totalWarnCount > 0, warnData: totalWarnData, warnHostnames: warnHostnames, isFatal: totalFatalCount > 0, fatalData: totalFatalData, fatalHostnames: fatalHostnames, logStart: r.LogStart, logEnd: r.LogEnd, } info.diffInfos = append(info.diffInfos, di) info.hostCheckInfo.checkAt = append(info.hostCheckInfo.checkAt, fmt.Sprintf("%s %s ~ %s", inst.InstanceName, di.logStart, di.logEnd)) } expectHosts := make(map[string]struct{}) for _, usage := range t.SenderUsage { expectInstances, err := instance.GetMRInstanceListByUsageAndStatuses(usage, opt.targetStatuses, opt.listInstanceMaxRetry) if err != nil { return nil, err } for _, ei := range expectInstances { expectHosts[ei.InstanceName] = struct{}{} } } notFoundHosts := []string{} for expectHostname := range expectHosts { if _, ok := actualHosts[expectHostname]; !ok { notFoundHosts = append(notFoundHosts, expectHostname) } } // 本来送ってくるはずのホストを検出 if len(notFoundHosts) > 0 { info.hostCheckInfo.notFoundHostnames = notFoundHosts } return &info, nil }
監視用のコードのメインロジックとなる部分を紹介しました。
対象usageのインスタンス情報を取得し、並列にHTTPリクエストを送信する処理については(1)の"up"チャンク監視と共通です。
タイムスタンプの差分はYAMLファイルでusageごとに指定した範囲によって、warnやfatalのアラートが必要か判別しています。warnやfatalの場合は、どの送信元からのログがどれくらい閾値を超過したのかをSlackに通知します。
また、期待される送信元のusageについてもYAMLファイルで指定しているので、到達したログのホスト名と比較して、期待される送信元usageの全てのインスタンスからログが転送されたかをチェックし、そうでない場合はSlackにfatal通知を行います。
参考として、log_to_metrics filter プラグインを使用すれば、標準メトリクスと同じHTTPサーバーの/metrics/エンドポイントでログを抽出してメトリクスを抽出することができます。
現在はcounter / gauge / histogramという3つのモードをサポートしていて、正規表現でログを絞り込みながら簡単にメトリクスを公開できます。例えばタイムスタンプの差分を監視するならば該当フィールドのhistogram、送信元インスタンスを監視するならば該当フィールドのcounterという実装ができそうです。
しかし、執筆時点でlog_to_metrics filterプラグインはexperimental featureであり、将来的に予告なく機能が変更される可能性があります。よってlog_to_metricsに依存しない形にするため、サイドカーコンテナを起動してメトリクスを公開する簡易サーバーを実装しました。
6. インターンを振り返って
ミラティブのインフラチームの特徴
私は今回、ミラティブのインフラチームで4ヶ月間インターンに参加させていただきました。ここでは、1人のインターン生から見たインフラチームの特徴を紹介させてください。
今回のインターンに応募したきっかけとしてインフラ領域に興味を持っていたことはもちろんありますが、決め手はミラティブのインフラ関連のテックブログでした。全てのブログの詳細までは追っていませんが、背景・目的から関連知識、実装、ベンチマークまでが凝縮された内容で、内製文化と技術力の高さが伝わってきました。
インターンに参加してからもその印象は変わらず、インフラチームから自分に足りないスキル・経験を無限に吸収できると再確認しました。
参加して間もない頃、検証用のVMインスタンスを作成したいと思い
「VMを立てたいのですがTerraformはどのリポジトリで管理していますか」
と当然のように質問したところ、メンターさんが
「実は内製のツールがあって...」
と答えてくださり、衝撃が走ったのを今でも覚えています。この内製CLIツールは、ミラティブのインフラに特化した多くの便利機能の集合体のようなもので、タスクを進めるごとにその便利さを痛感することになりました。
内製技術が多いことは参入障壁になると思われがちですが、知らないことだらけで身動きが取れなかった私にもチームの皆さんがその都度丁寧に説明してくださったので内製技術の恩恵を十分に受けることができました。
インターン期間でチームの皆さんのタスクを把握することはできませんでしたが、大規模サービスを支える少人数インフラチームの技術力の高さにはたくさん刺激を受けました。
4ヶ月のインターンで学んだこと
今回のインターンで学んだことは数え切れませんが、個人的にインパクトの大きかった2つを紹介させていただきます。
まず1つ目は、深い部分まで理解してプログラムを書くことです。今回のインターンではGoを書くことが多かったのですが、たとえ標準ライブラリであってもその内部実装や(システムプログラミングの文脈で)低レベルな仕組みまで理解してコードを書くことの重要性を知りました。
今回のFluent Bit移行タスク関連の実装だけでも、シグナル、ファイルディスクリプタ、正規表現、CPU/メモリ負荷などのトピックが登場しました。その度にメンターさんがGoでサクッと実験用のコードを書いてくださったので、実際にプログラムを実行することで表面的な知識が活きた知識になりました。
それから2つ目は、アクションを起こす前に自分で調査して不安や疑問をなくすことです。今回取り組んだFluent Bit移行のタスク以外にも、交代でdependabotの対応に挑戦しました。先述したように内製技術が多いためキャッチアップが難しかったですが、分からないことがある場合に何を考えてどう調査を始めると良いかアドバイスをいただきました。4ヶ月前の自分に比べれば、インフラ領域で自立的に動くための基礎知識や習慣が身に付いたと思います。
最後にインフラチームのインターンはこういう人にオススメという点を書きます。幅広く応用が効くインフラの基礎体力をつけたい人はもちろん、想像していたよりもコードを書く機会が多いのでコードを書くのが好きな人にオススメできると思います。
私はこれまでインターンに複数参加してきましたが、取り組むべきタスクはありつつもインターン生の基礎力を伸ばすことを全力でサポートしてくれるインターンは貴重だと感じたので改めて感謝いたします。
7. まとめ
本記事では、ミラティブのログ基盤をFluentdからFluent Bitへ部分移行した経緯と実際の移行プロセス、そしてFluent Bitの監視ツールの実装について紹介しました。
今回のインターンはログ欠損の原因調査から始まり、さまざまな観点を考慮したうえでFluent Bitへの移行を決定しました。技術的な理解が深まっただけでなく、特にインフラという領域で調査と実践を繰り返す重要性を学ぶことができました。
インターン期間でインフラチームの皆さんにはたくさんサポートしていただきました。メンターのhataさんには、タスクの掘り下げから負荷試験、アイデアの相談、コードレビュー、オペレーションのサポートまで大変お世話になりました。また、頻繁に#timesを覗きにきて的確なアドバイス・サポートをしてくださったkondoさんをはじめとして、困った時に圧倒的スピード&技術力で助けてくださったインフラチームの皆さんに改めて感謝を伝えたいです。
ありがとうございました。
We are Hiring!
ミラティブのインターンに興味が湧いた方は以下のリンクからどうぞ!
*1:Google CloudのCloud Loggingも入れると正確には3通りあります
*2:Fluentd v0.12を使用した結果であるため、他のバージョンでは挙動が異なる可能性があります
*3:read_from_headパラメータをtrueとしている場合は、監視対象に追加されるよりも前に書き込まれたログはFluentdによって読み込まれ、処理されます