こんにちは、ミラティブのインフラを担当している清水です。 今回はミラティブのデータベースのマスタをどのようにフェイルオーバさせているかノウハウをお伝えしようかと思います。
ミラティブではデータベースにMySQLを利用しており、マスタ・スレーブ構成で冗長化しています。 マスタ・スレーブ構成の優れている点はデータをフルダンプすればデータベースを完全に複製でき、マルチマスタ構成で発生しうるデータ不整合を気にかけなくて良い点です。 データベースのクラスタリングには MySQL Cluster や GaleraCluster などもありますが、マスタ・スレーブ構成はストレージエンジンに依存せず素のMySQLで運用できるので、クラスタ固有の制約にハマったりせずシンプルに運用できるのも強みです。
ただし、マスタ・スレーブ構成の鬼門となるのがマスタのフェイルオーバです。 スレーブは参照のみリクエストを処理するので1台停止しても別のスレーブから再び参照すればよいだけなので復旧が容易です。 一方でマスタは、データの書き込み処理を行っているため、フェイルオーバ時にはデータ不整合なく書き込み先を切り替える必要があります。
生きているスレーブをマスタに昇格するにしても、
- スレーブが複数台ある場合はデータ欠損を最小とするため、もっともRelaylogのポジションの進んだスレーブを探し出してマスタ昇格候補にする
- スレーブが複数台ある場合はRelaylogのポジションにズレがないか確認し、ズレが発生していたら欠損しているバイナリログを手動で解消させる
- マスタ昇格候補のスレーブにレプリケーションを張り直す
といった作業が発生します。
とても慎重且つ神経を使う作業が要求されますが、作業中にユーザさんはサービスを完全な状態で利用できないわけで、焦りや緊張でオペレーションミスを誘発しかねません。
そこで、ミラティブではマスタ切り替えにMHA for MySQL(Master High Availability Manager and tools for MySQL)というHAツールを利用して、データ不整合を最小限に解消させ、安全且つ短時間にフェイルオーバを行えるようにしています。
MHA for MySQL(Master High Availability Manager and tools for MySQL)とは
MHA for MySQL(以下、MHAと略す)はDeNA社がオープンソースとして公開している MySQL の HAツールで、githubにソースコードが公開されています。
MHAはMySQLサーバにmha4mysql-nodeをインストールし、外部サーバからmha4mysql-managerに含まれるスクリプトを動かしてフェイルオーバを行います。 インストール方法は本家 mha4mysql wiki で解説されているので本記事では割愛します。
MHAを利用すれば複雑なマスタのフェイルオーバ作業をワンコマンド化することができ、デーモンとして動かしておけば自動化させることもできますが、動かすためにいくつか注意点もあります。
一つ目はスレーブでもBinlogを吐くようにしておく必要があることです。 これはMHAがマスタ・スレーブをフェイルオーバさせた時にマスタからBinlogを回収してスレーブとの差分を埋めてくれるためで、Binlogが吐かれていないとスレーブがマスタ昇格後にMHAを実行できなくなってしまうからです。
二つ目はマスタと昇格対象のスレーブのスペックを揃えておくことです。 マスタ昇格後にスペックが下がってしまうようなことがあると、もともと捌けていたリクエストを昇格後に捌くことができず障害になりかねないからです。
ミラティブではマスタと昇格対象のスレーブはスペックを揃えてBinlogを吐くように運用していて、いつでもスレーブをマスタに昇格できるようにしています。
MHAの処理の流れを追ってみる
MHAを実行した時にどのような制御をしてマスタのフェイルオーバを行っているのか紹介します。 ここの所を理解しておけばMHAの実行に失敗してもパニックにならず落ち着いて作業できるかと思います。
mha4mysql-managerに含まれるmasterha_master_switchを利用してマスタをフェイルオーバした時の処理の流れを見て行きましょう。
マスタが停止している場合
マスタが停止してしまったときのMHAの処理を見ていきましょう。 MHAは切り替えをPhaseで管理しており、マスタが停止している場合はPhase1~5まで進んでフェイルオーバが完了します。
- Phase 1: Configuration Check Phase..
- Phase 2: Dead Master Shutdown Phase..
- Phase 3: Master Recovery Phase..
- Phase 3.1: Getting Latest Slaves Phase..
- Phase 3.2: Saving Dead Master's Binlog Phase..
- Phase 3.3: Determining New Master Phase..
- Phase 3.3: New Master Diff Log Generation Phase..
- Phase 3.4: Master Log Apply Phase..
- Phase 4: Slaves Recovery Phase..
- Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
- Phase 4.2: Starting Parallel Slave Log Apply Phase..
- Phase 5: New master cleanup phase..
Phase 1: Configuration Check Phase..
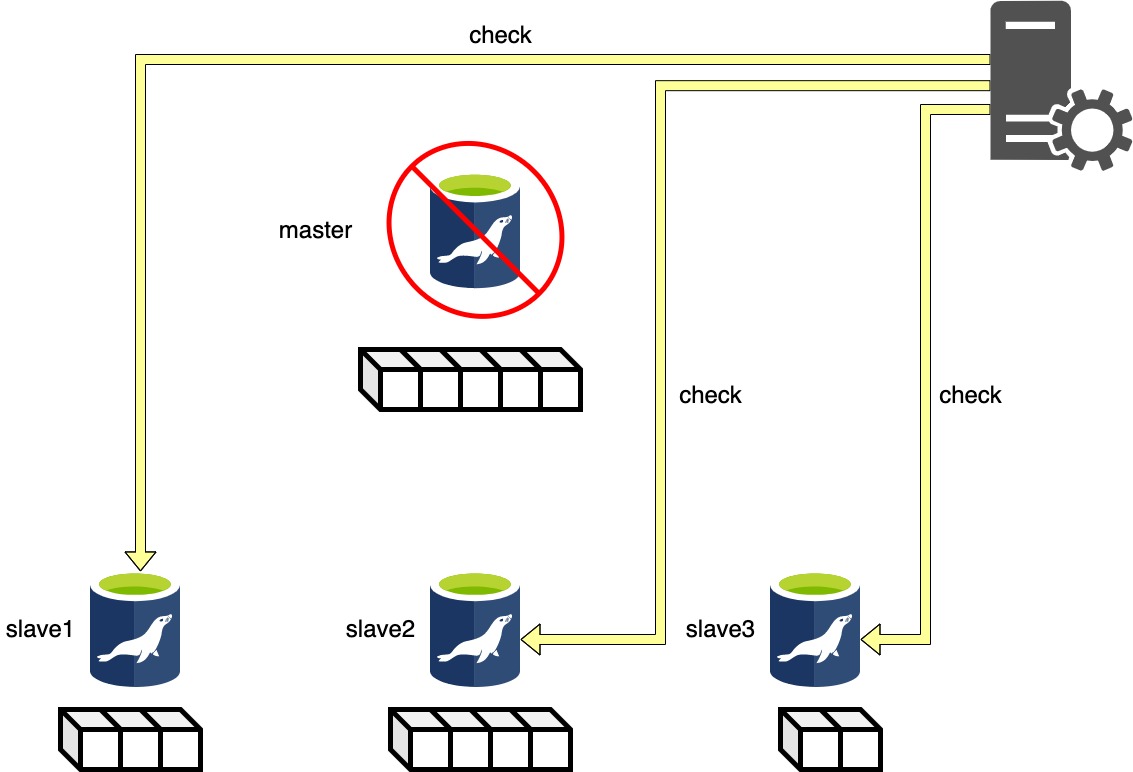
Phase1はMHAのconfを検証してくれます。 MHAのconfは環境ごとに異なりますが、概ねこのような設定を記述します。
[server default]
user=${MYSQL_USER}
password=${MYSQL_PASSWORD}
repl_user=${REPL_USER}
repl_password=${REPL_PASSWORD}
remote_workdir=/path/to/workdir
master_binlog_dir=/path/to/mysql
ssh_user=${SSH_USER}
master_pid_file=/path/to/mysqld.pid
master_ip_failover_script=/path/to/master_ip_failover_script
master_ip_online_change_script=/path/to/master_ip_online_change_script
shutdown_script=/path/to/shutdown_script
report_script=/path/to/report_script
manager_workdir=/path/to/workdir
manager_log=/path/to/mha/log
[server1]
hostname=${SERVER1}
ip=${ADDRESS1}
[server2]
hostname=${SERVER2}
ip=${ADDRESS2}
candidate_master=1
[server3]
hostname=${SERVER3}
ip=${ADDRESS3}
candidate_master=1
[server4]
hostname=${SERVER4}
ip=${ADDRESS4}
candidate_master=0
MHAのconf内容が間違っていたり、スレーブが停止していたり、スレーブにssh接続できないときはPhase1で中断されます。 この段階でマスタ切り替えは行われていないので、落ち着いてconf内容と実際に動いているマスタ・スレーブ構成を見直してみて下さい。
Phase 2: Dead Master Shutdown Phase..
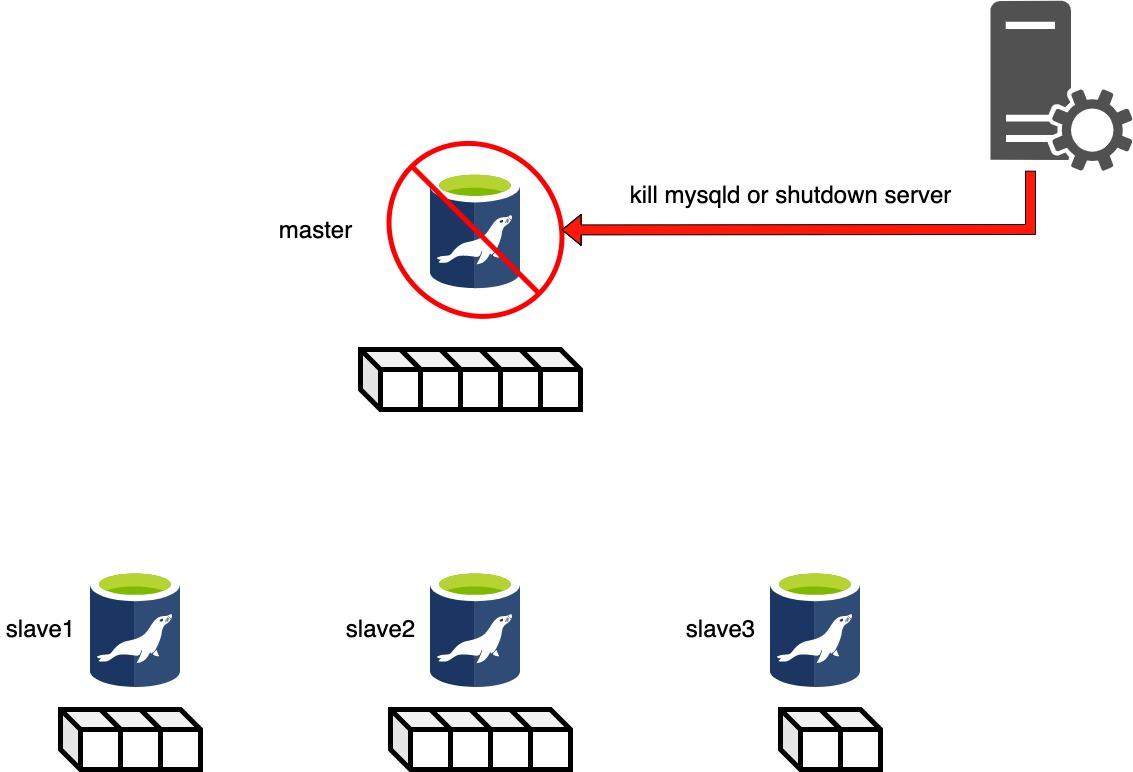
Phase2は停止したマスタを完全停止させます。 ハングアップしたと思われていたマスタが実は生きていて、マスタ切替中にアプリケーションからデータの書き込みが発生してデータ不整合が発生することを防いでくれます。
Phase2に入るとまず master_ip_failover_scriptが--command=stop|stopssh 引数とともに実行されます。
/path/to/master_ip_failover_script \
--command=stop|stopssh \
--orig_master_host=${ORIG_MASTER_HOST} \
--orig_master_ip=${ORIG_MASTER_IP} \
--orig_master_port=${ORIG_MASTER_PORT}
Phase2で実行されるmaster_ip_failover_scriptはこれからマスタを完全停止するための事前処理を記述して実行します。 例えば、停止したマスタのレコードを引けなくしたり、これから停止するマスタの情報を通知させたりできますが、何もさせたくない場合は処理を記述しなければよいです。
mha4mysql-managerに master_ip_failover というサンプルスクリプトが付属しているので、サンプルを参考にしつつ自前で処理を記述してみましょう。 Perl製ですが、同じ引数を受け取ることができれば別言語でも実装可能です。
続いて、マスタを完全停止させるためshutdown_script が実行されます。
/path/to/shutdown_script \
--command=stop \
--host=${HOSTNAME} \
--ip=${ADRESS} \
--port=${PORT} \
--pid_file=/path/to/mysqld.pid
mha4mysql-managerに power_manager というshutdown_scriptがスクリプトが付属していますが、ミラティブのMySQLデータベースはGCP(Google Cloud Platform)で動いており、GCPと連携して確実にマスタを停止させたかったのでGo製のツールを自作しています。 このGo製のマスタ停止ツールはssh越しにMySQLの停止を試みて、失敗した場合はGCPからインスタンスを強制停止してくれます。
例ですが、shutdown_scriptはこんな感じで実装しています。
package main
import(
"fmt"
"log"
"gopkg.in/urfave/cli.v1"
"infra-tool"
"infra-tool/util"
"infra-tool/mha"
)
func mha_shutdown(c *cli.Context) error {
...
sshPrivateKey := c.String("ssh-private-key")
maxRetry := uint64(c.Int("max-retry"))
project := c.String("project")
if util.FileExists(sshPrivateKey) != true {
return fmt.Errorf("ssh-private-key not exist: %s", sshPrivateKey)
}
if maxRetry < 1 {
maxRetry = 1
}
// port22 に接続できないと--ssh_user が引数に渡されないのでrootを引き渡す
sshUser := c.String("ssh_user")
if c.String("ssh_user") == "" {
sshUser = "root"
}
mhaOptions := mha.MHAShutdownOptions{}
mhaOptions.Command = c.String("command")
mhaOptions.SshUser = sshUser
mhaOptions.Host = c.String("host")
mhaOptions.Ip = c.String("ip")
mhaOptions.Port = c.Int("port")
mhaOptions.PidFile = c.String("pid_file")
log.Printf("debug: command: %s", mhaOptions.Command)
log.Printf("debug: ssh_user: %s, host: %s, ip: %s, port: %d, pid_file: %s",
mhaOptions.SshUser, mhaOptions.Host, mhaOptions.Ip, mhaOptions.Port, mhaOptions.PidFile,
)
if mhaOptions.Command == "stopssh" || mhaOptions.Command == "stop" {
if err:= shutdownStopsshCommand(mhaOptions, sshPrivateKey, maxRetry, project); err != nil {
return err
}
}
return nil
}
func shutdownStopsshCommand(mhaOptions mha.MHAShutdownOptions, sshPrivateKey string, maxRetry uint64, project string) error {
if err := mha.KillMySql(mhaOptions.Host, mhaOptions.Ip, mhaOptions.SshUser, sshPrivateKey, maxRetry, mhaOptions.PidFile, project); err != nil {
log.Printf("warn: %s", err.Error())
if err := mha.ShutdownInstance(mhaOptions.Host, project); err != nil {
return err
}
}
return nil
}
func init(){
addCommand(cli.Command{
Name: "mha-shutdown",
Usage: "mha shutdown_script",
Flags: []cli.Flag{
cli.StringFlag{
Name: "ssh-private-key",
Usage: "/path/to/.ssh/id_rsa",
Value: watch.DEFAULT_MS_SSH_PRIVATE_KEY,
EnvVar: "INFRA_WATCH_MS_SSH_PRIVATE_KEY",
},
cli.IntFlag{
Name: "max-retry",
Usage: "maximum number of times to retry on failure",
Value: watch.DEFAULT_MS_MAX_RETRY,
EnvVar: "INFRA_WATCH_MS_MAX_RETRY",
},
cli.StringFlag{
Name: "project",
Usage: "specify gcp project",
Value: watch.DEFAULT_MS_PROJECT,
EnvVar: "INFRA_WATCH_MS_PROJECT",
},
cli.StringFlag{
Name: "command",
...
},
cli.StringFlag{
Name: "ssh_user",
...
},
cli.StringFlag{
Name: "host",
...
},
cli.StringFlag{
Name: "ip",
...
},
cli.IntFlag{
Name: "port",
...
},
cli.StringFlag{
Name: "pid_file",
...
},
},
Action: mha_shutdown,
})
}
Phase2で失敗した場合はmaster_ip_failover_scriptまたはshutdown_scriptの実行に失敗しているので、スクリプトをデバッグしてみてください。 スクリプトでマスタを落とし切ることができずエラー判定となる場合は手動で落としてしまうのも手です。
Phase 3: Master Recovery Phase..
Phase3はスレーブをマスタに昇格させるための下準備を進めるフェーズです。 3.1 ~ 3.4 まであるのでそれぞれ見ていきましょう。
Phase 3.1: Getting Latest Slaves Phase..
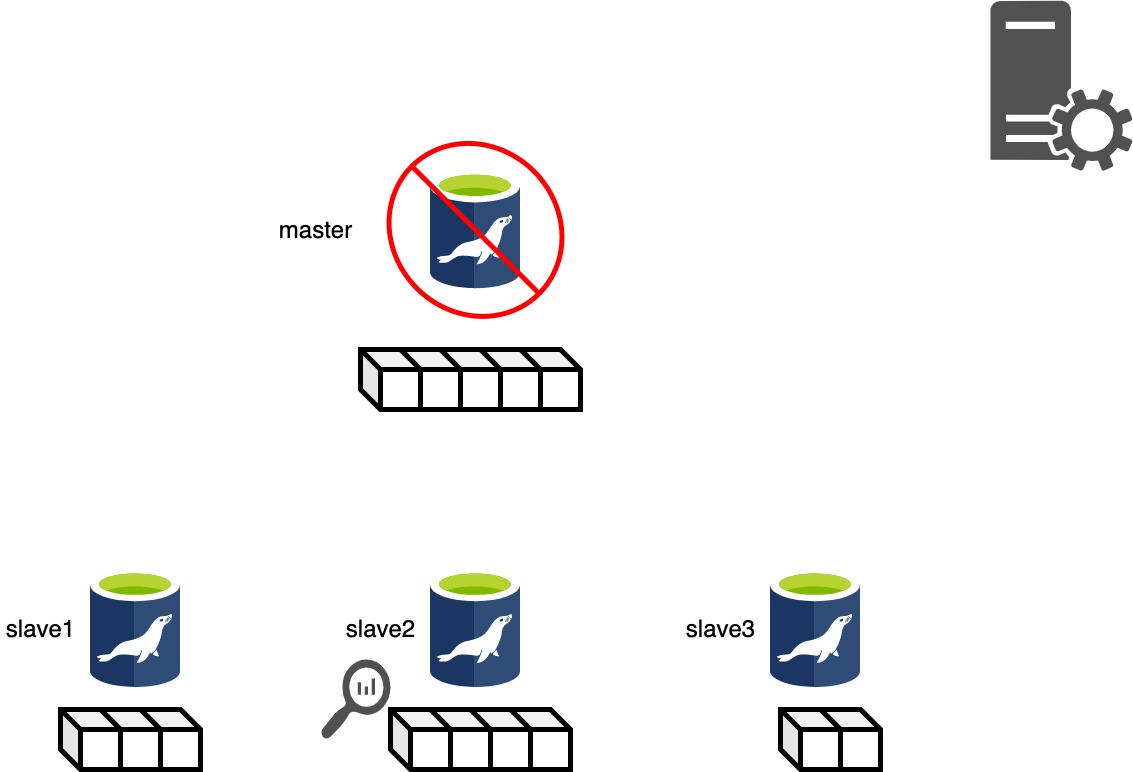
Phase3.1は全てのスレーブのRelaylogポジションをチェックしてもっともポジションの進んでいるスレーブを探し出します。 図ではSlave2がもっともポジションの進んだsalveです。
Phase 3.2: Saving Dead Master's Binlog Phase..
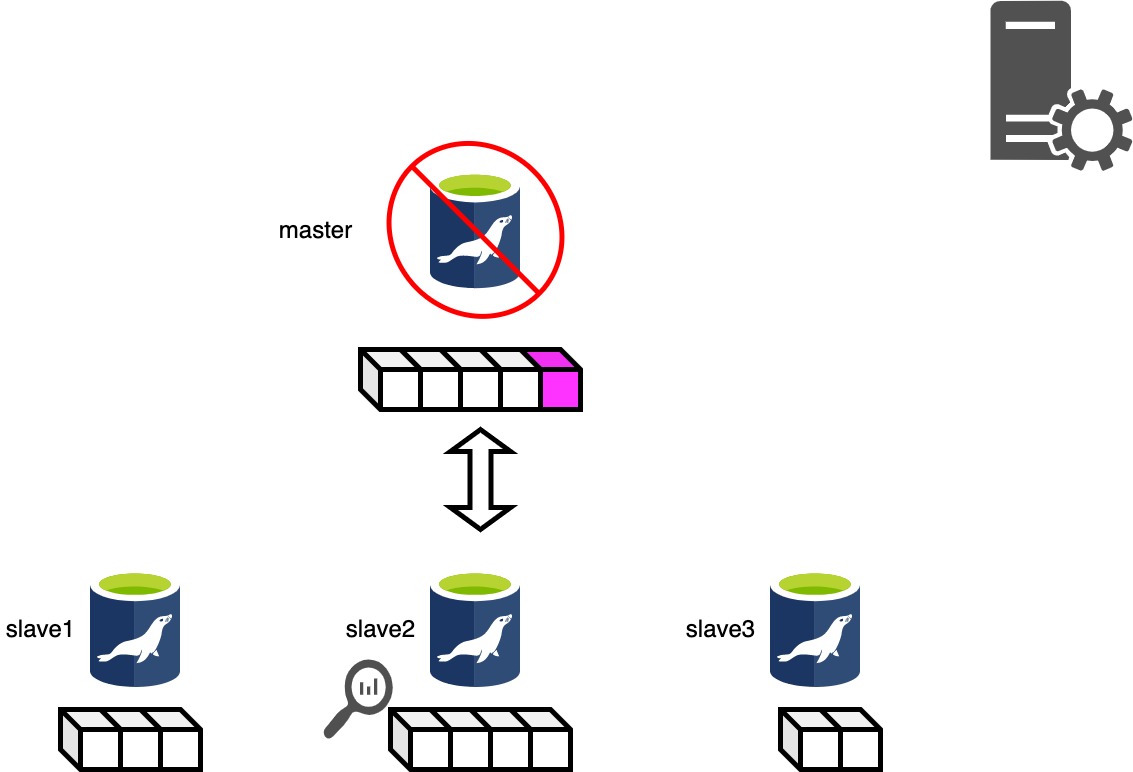
Phase3.2は停止したマスタにsshログインを試行し、もっともRelaylogポジションの進んだスレーブと停止したマスタのBinlogポジションの差分を回収します。 インスタンスが停止してしまっている場合はsshログインできないのでスキップされます。
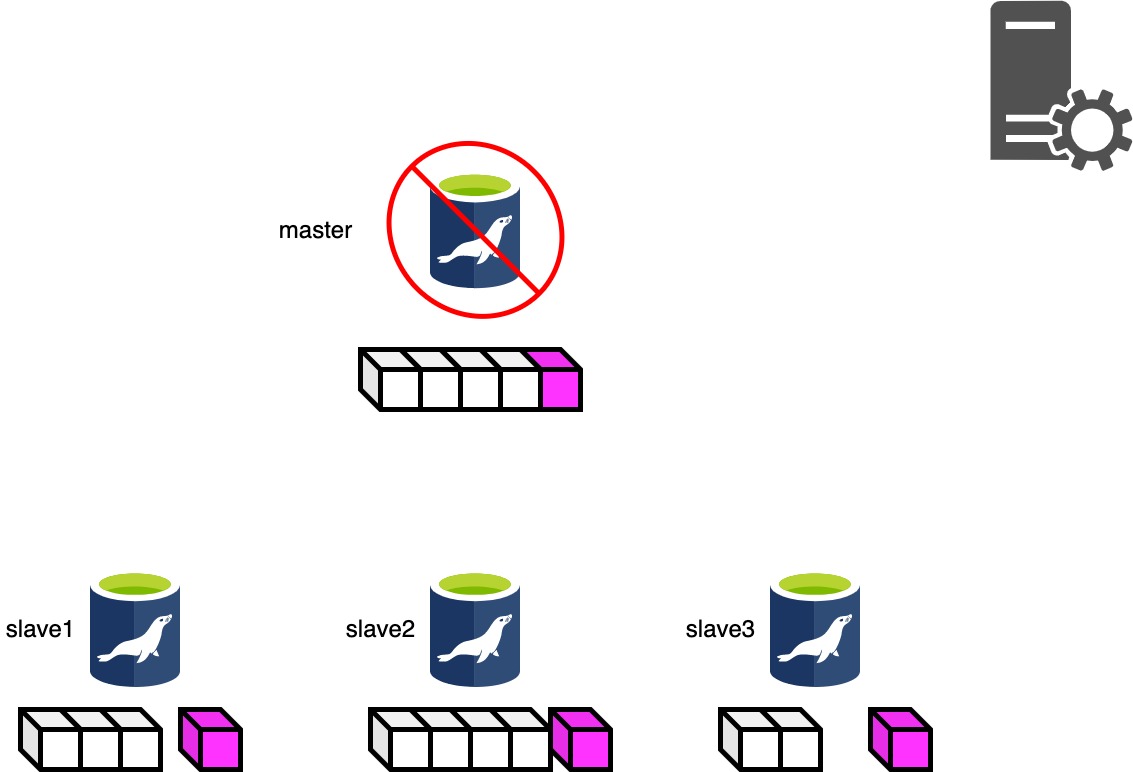
停止したマスタからBinlogの回収に成功した場合は全てのスレーブに差分を転送します。
Phase 3.3: Determining New Master Phase..
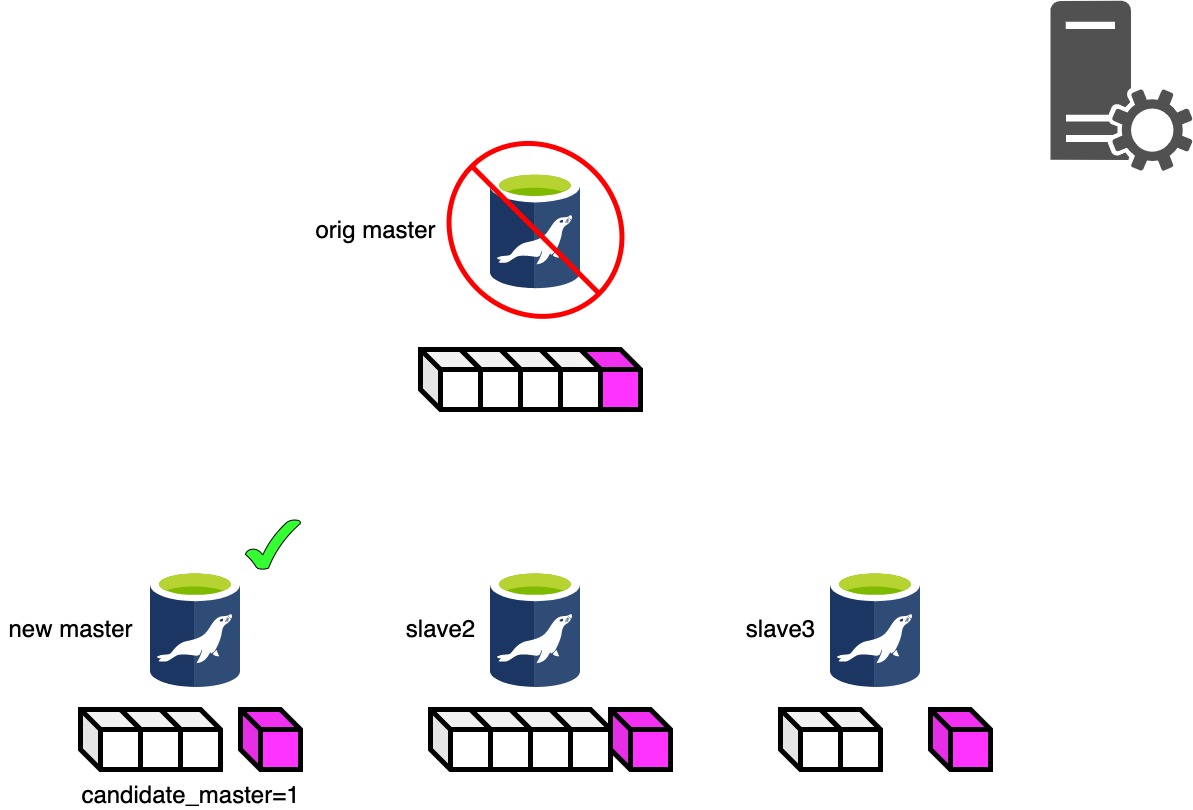
Phase3.3パート1はマスタの昇格候補となるスレーブを決定します。
もっともRelaylogポジションの進んでいるスレーブが昇格候補となりますが、MHAのconfに candidate_master=1 を定義すると優先的に特定のスレーブを昇格候補とすることができます。
Phase 3.3: New Master Diff Log Generation Phase..
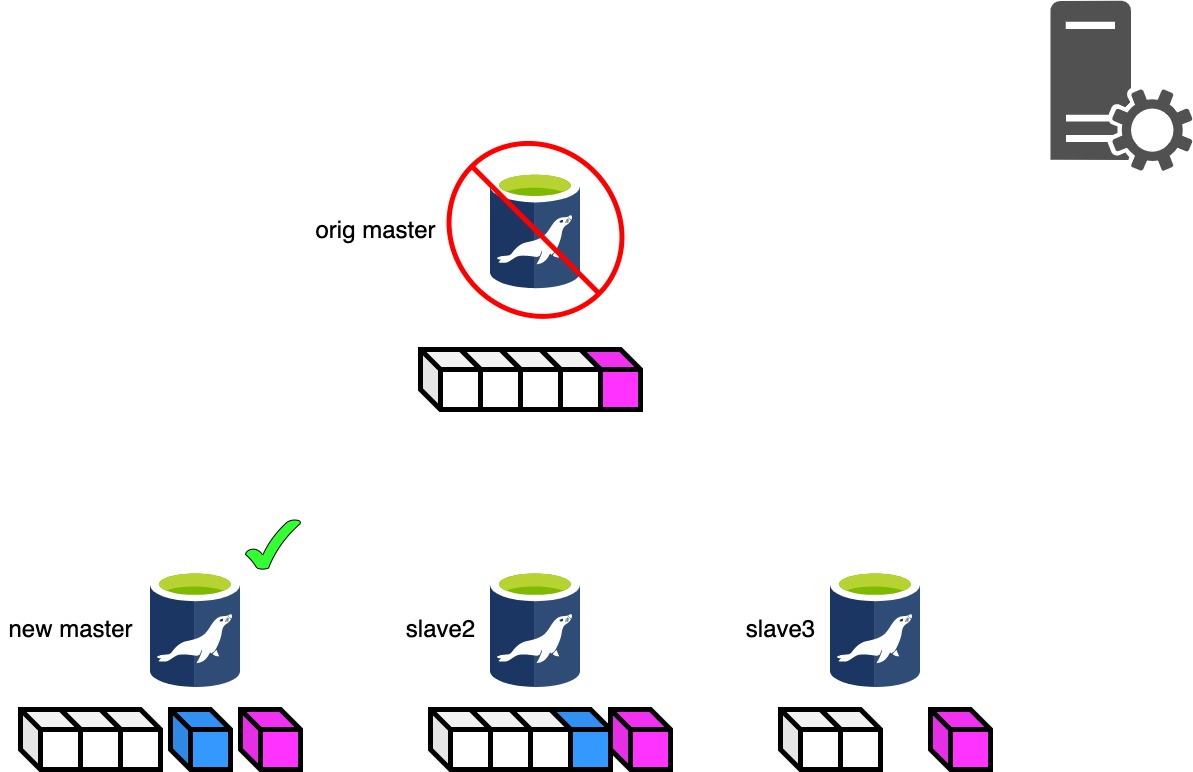
Phase3.3パート2はもっとものRelaylogポジションの進んでいるスレーブとマスタ昇格候補スレーブのRelaylogの差分を取り出し、マスタ昇格候補スレーブに転送します
Phase 3.4: Master Log Apply Phase..
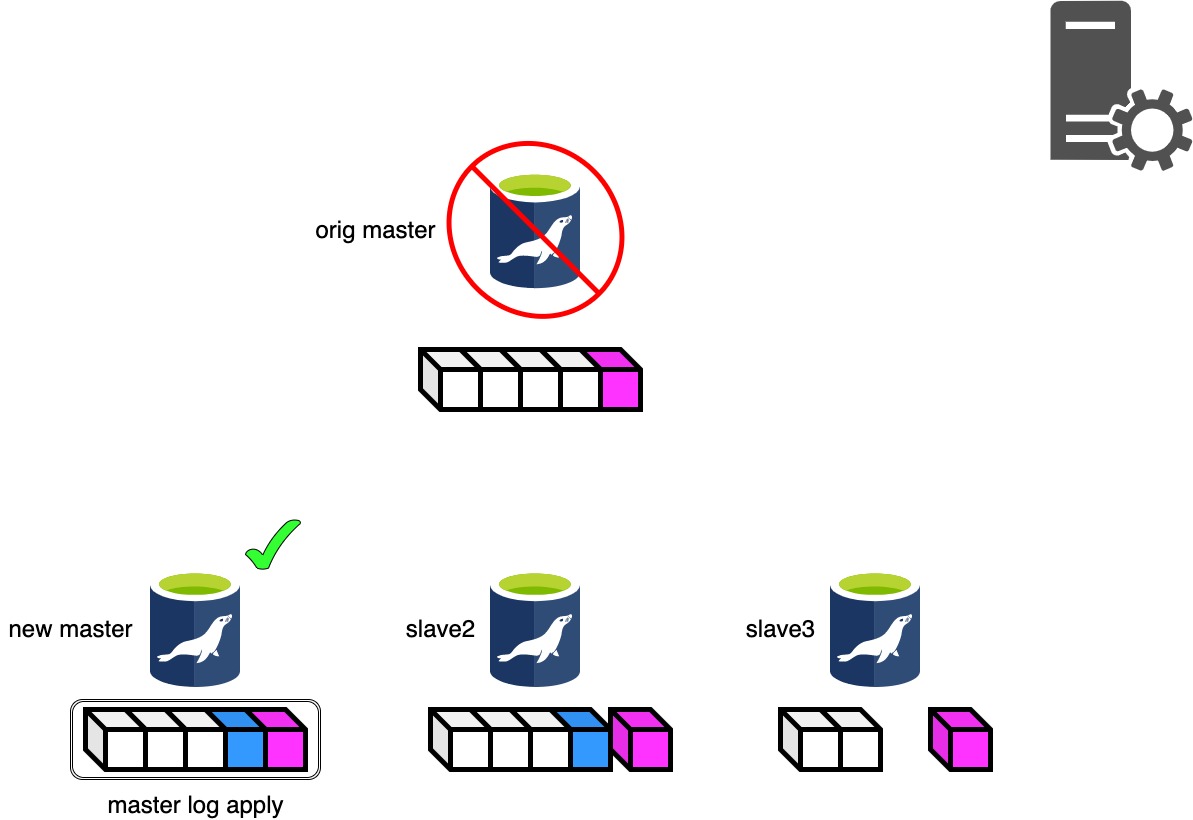
Phase3.4はマスタ昇格候補のスレーブに停止したマスタから回収したBinlogの差分と、もっともRelaylogポジションの進んでいるスレーブとの差分を適用します。
ここまで進むともう後戻りはできません。差分適用に失敗したら戻すのは困難なので壊れていない他のslaveからdumpを取ってマスタ・スレーブを作り直した方が早いです。 無事終わることを見守りましょう。
差分適用に成功したらmaster_ip_failover_scriptが--command=start引数とともに実行されます。
/path/to/master_ip_failover_script \
--command=start \
--ssh_user=${SSH_USER} \
--orig_master_host=${ORIG_MASTER_HOST} \
--orig_master_ip=${ORIG_MASTER_IP} \
--orig_master_port=${ORIG_MASTER_PORT} \
--new-master_host=${NEW_MASTER_HOST} \
--new_master_ip=${NEW_MASTER_IP} \
--new_master_port=${NEW_MASTER_PORT} \
--new_master_user=${NEW_MASTER_USER} \
--new_master_password=${NEW_MASTER_PASSWORD}
Phase 3.4で実行されるmaster_ip_failover_scriptはアプリケーションの書き込み先をマスタ昇格候補のスレーブに切り替えるための処理を記述します。 DNSで制御している場合はマスタのレコードを切り替えたり、IPで書き込み先を制御している場合はIPを付け替えたりします。
Phase 4: Slaves Recovery Phase..
Phase4はマスタ昇格候補のスレーブとその他スレーブの差分を埋めてレプリケーションを張り直します。
Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
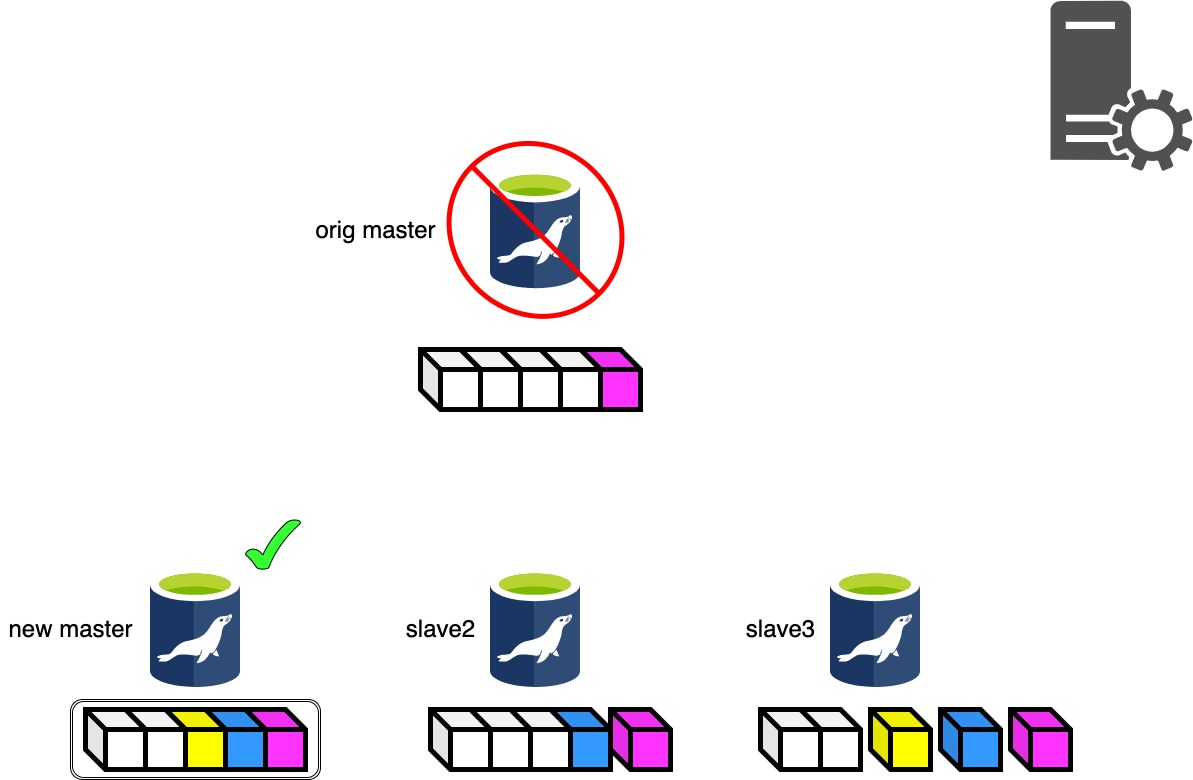
Phase 4.1はマスタ昇格候補のスレーブとその他スレーブのRelaylogの差分を生成してそれぞれのスレーブに転送します。
Phase 4.2: Starting Parallel Slave Log Apply Phase..
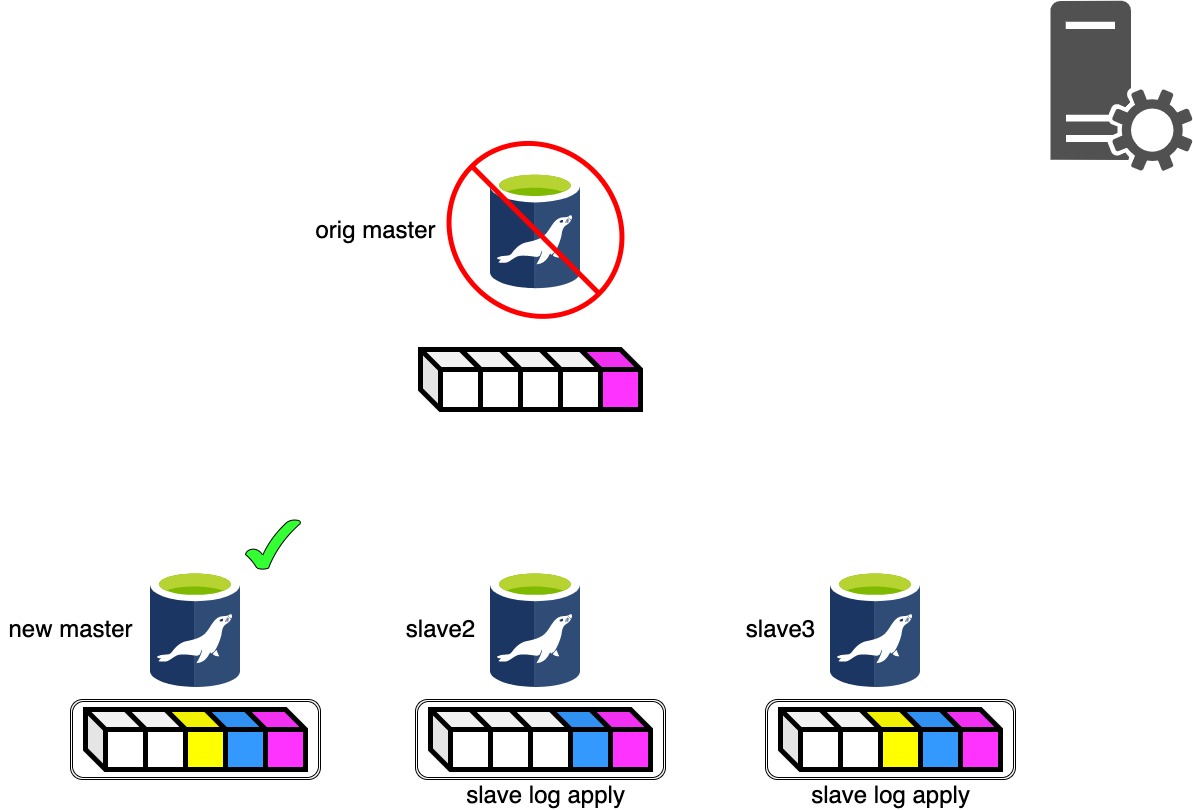
Phase 4.2は各スレーブで停止したマスタから回収したBinlogの差分と、もっともRelaylogポジションの進んでいるスレーブとの差分を適用します。 ここで差分適用に失敗してしまってもマスタ昇格候補のスレーブは復元が完了しているので、そこからダンプを取ってスレーブを作り直しましょう。
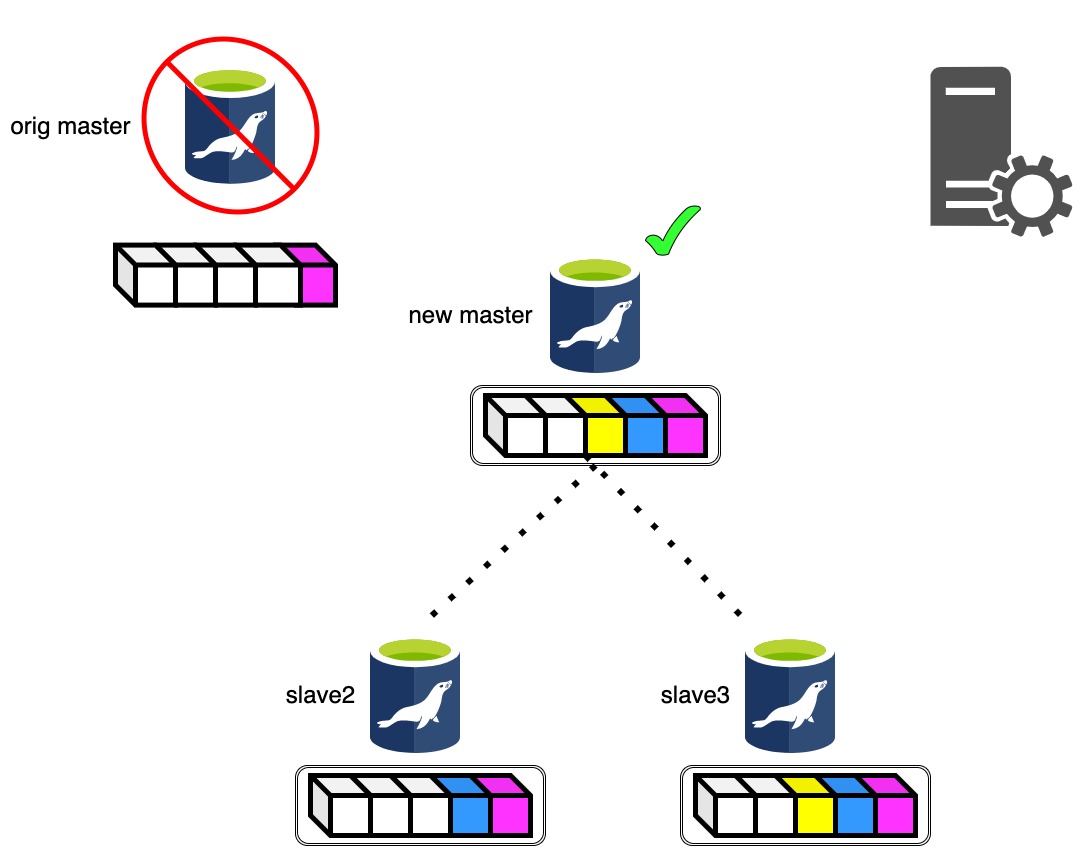
差分適用に成功したらマスタ昇格候補のスレーブにレプリケーションを張り直します。
Phase 5: New master cleanup phase..
Phase5はマスタ昇格候補のスレーブで reset slave all が実行されて、停止したマスタとレプリケーションを張っていたときの情報がクリーニングされます。
Master failover to ${HOSTNAME}(${ADDRESS}:${PORT}) completed successfully.
メッセージが表示されればマスタ切り替えは完了です。おつかれさまでした。
マスタが起動している場合
マスタが停止せずともスレーブをマスタに昇格させたい場合もよくあります。 例えば、CPUやメモリといったサーバのスペックを増強したり、コスト最適化のためにディスク容量を減らしたり、サーバの性能劣化による入れ替えを行いたいケースなどです。
停止メンテナンスを伴う時間を確保すれば切り替えはできますが、ユーザへの告知、サービス連携している協力会社さんへの連絡、停止中のユーザアクセスの停止が発生するためできればやりたくはありません。 MHAはマスタが起動状態でも切り替えられるように作られているので停止メンテナンスを伴う時間を確保せずとも切り替えることができます。
それでは、マスタが起動している場合のmasterha_master_switchの挙動を見ていきましょう。 マスタが起動している場合のPhaseは1,2,5で、マスタが停止している場合と異なるのはBinlogとRelaylogの差分回収と適用が無い点です。
- Phase 1: Configuration Check Phase..
- Phase 2: Rejecting updates Phase..
- Phase 5: New master cleanup phase..
Phase 1: Configuration Check Phase..
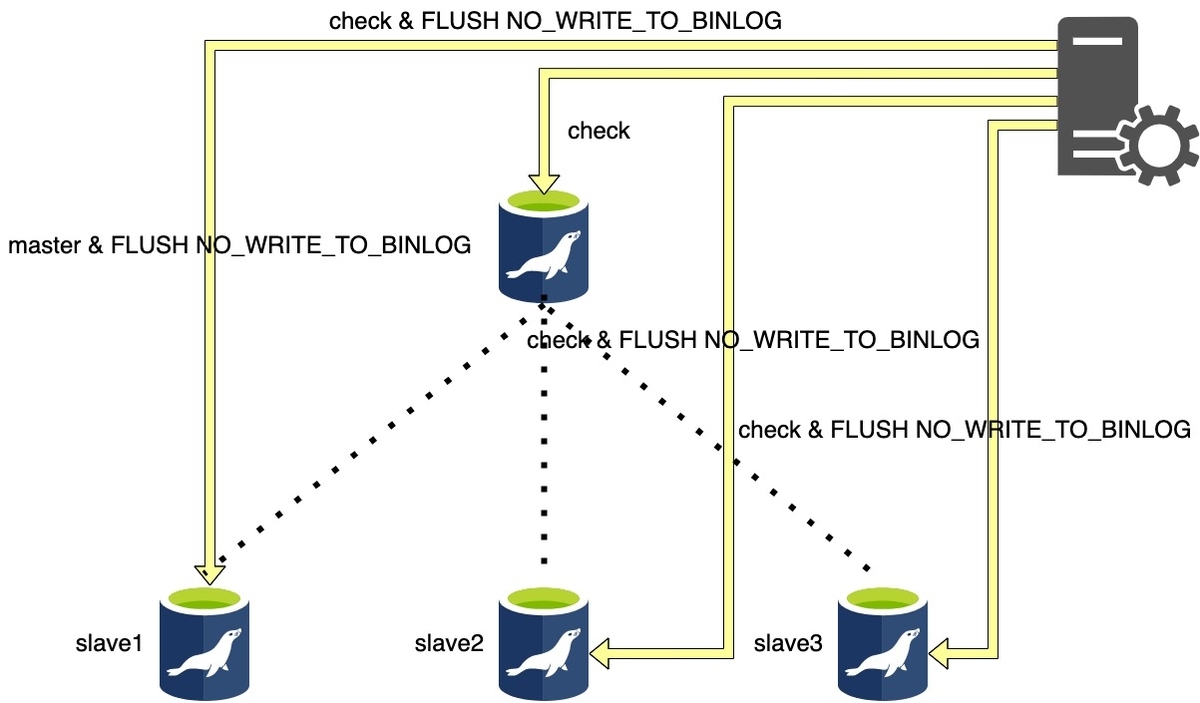
Phase1はマスタが停止している時と概ね同じ挙動をします。 スレーブが停止していたりssh接続できないときはPhase1で中断されるので、落ち着いてMHAのConf内容とマスタ・スレーブ構成の状態を見比べてみましょう。
マスタが停止している場合と異なる挙動はPhase1で FLUSH NO_WRITE_TO_BINLOG が実行されてBinlogの書き出しが行われる点です。
書き込みが多いとIO詰まりを誘発しかねないので、書き込みの少ない時間帯にあらかじめ1台ずつ FLUSH NO_WRITE_TO_BINLOG を実行しておくと安全です。
もし IO に余裕がある環境であれば、 cron などで FLUSH NO_WRITE_TO_BINLOG を定期実行しておき、 Binlog を定期的に書き出しておくのも有効かもしれません。
Phase 2: Rejecting updates Phase..
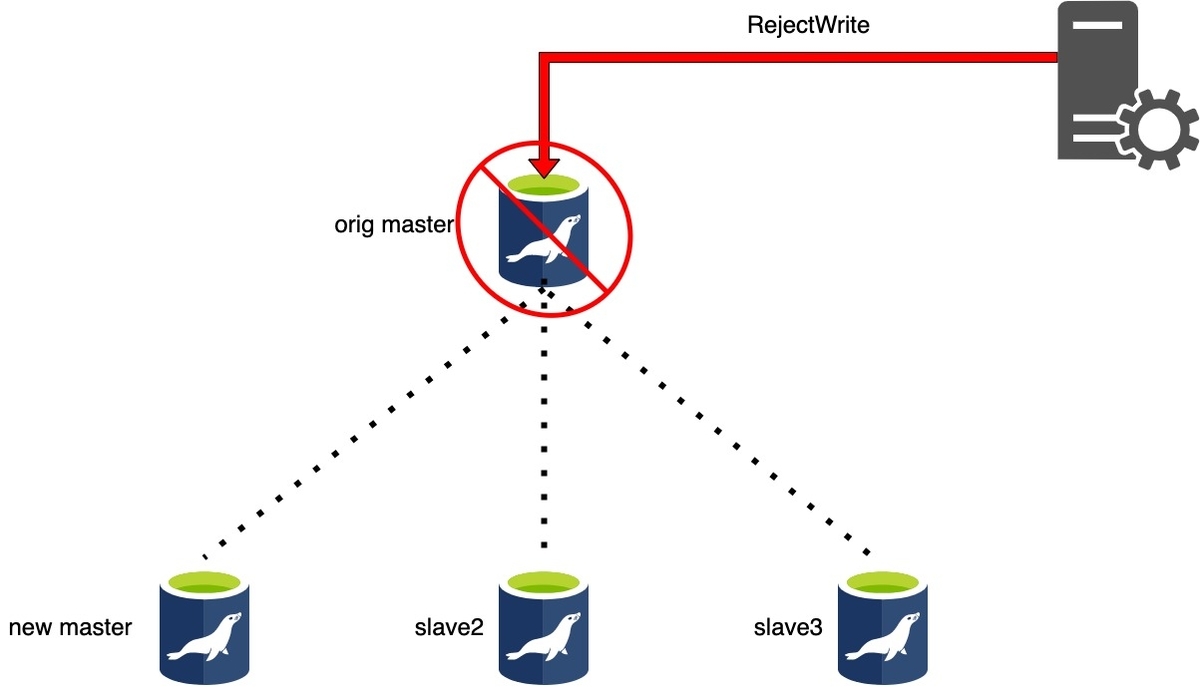
Phase2はマスタ切り替え中のデータ不整合を防ぐためにアプリケーションからの書き込みをブロックします。
書き込みのブロックはmaster_ip_online_change_scriptが --command=stop|stopssh 引数とともに呼び出されて行ってくれます。
/path/to/master_ip_online_change_script \
--command=stop|stopssh \
--orig_master_host=${ORIG_MASTER_HOST} \
--orig_master_ip=${ORIG_MASTER_IP} \
--orig_master_port=${ORIG_MASTER_PORT} \
--orig_master_user=${ORIG_MASTER_PORT} \
--orig_master_password=${ORIG_MASTER_PASSWORD} \
--new_master_host=${NEW_MASTER_HOST} \
--new_master_ip=${NEW_MASTER_IP} \
--new_master_port=${NEW_MASTER_PORT} \
--new_master_user=${NEW_MASTER_USER} \
--new_master_password=${NEW_MASTER_PASSWORD} \
--orig_master_ssh_user=${ORIG_MASTER_SSH_USER} \
--new_master_ssh_user=${NEW_MASTER_SSH_USER}
mha4mysql-managerに master_ip_online_change がサンプルスクリプトとして付属しているので環境にあわせてカスタマイズしてみましょう。
ミラティブではアプリケーション用のMySQLユーザを以下表のとおり書き込み用と参照用を分けており、 Goで実装したmaster_ip_online_change_script が書き込み用ユーザをアンダースコア付きのユーザ名にrenameして新規の書き込み用のセッションを落としています。
| 書き込みユーザ | 参照ユーザ | |
|---|---|---|
| master | writeuser | readuser |
| slave1 | _writeuser | readuser |
| slave2 | _writeuser | readuser |
| slave3 | _writeuser | readuser |
持続的な接続があると効果が無いので注意が必要ですが、ミラティブのアプリケーションは切り替えを考慮して処理毎に都度、接続を切断して接続が残らないように実装しています。
一般的なサービスではmysql接続時のオーバヘッドを減らす目的でkeepaliveで実装されていますが、ミラティブはフェイルオーバ発生時のダウンタイムを極力減らす目的でコネクションプールでも長時間接続が残らないようにしています。 持続的な接続に比べオーバヘッドも含んでしまいますが、接続がmax-connectionになるまで溜まることもほとんどなくなります。
万が一書き込みを復旧させたい時でも、MySQLユーザをrenameしているだけなので切り戻しも簡単です。 また、書き込み先を1箇所に限定できるので切り替え中に意図せぬスレーブへアプリケーションが書き込んでしまう事故も防げます。
master_ip_online_change_script で安全に新規書き込みの接続を落とすことができたら、 FLUSH TABLES WITH READ LOCK でテーブルロックされて完全に書き込みできない状態となり、マスタの切り替えが開始されます。
まず、master_ip_online_change_scriptが --command=start とともに呼び出されます。
ここではマスタ昇格先のスレーブで書き込みを行えるようにするための処理を記述しておきます。
ミラティブの場合ですと、書き込み用ユーザをアプリケーションが利用できるようにrenameして、DNSを切り替えてAレコードを昇格したマスタに向けるように実装しています。
/path/to/master_ip_online_change_script \
--command=start \
--orig_master_host=${ORIG_MASTER_HOST} \
--orig_master_ip=${ORIG_MASTER_IP} \
--orig_master_port=${ORIG_MASTER_PORT} \
--orig_master_user=${ORIG_MASTER_USER} \
--orig_master_password=${ORIG_MASTER_PASSWORD} \
--new_master_host=${NEW_MASTER_HOST} \
--new_master_ip=${NEW_MASTER_IP} \
--new_master_port=${NEW_MASTER_PORT} \
--new_master_user=${NEW_MASTER_USER} \
--new_master_password=${NEW_MASTER_PASSWORD} \
--orig_master_ssh_user=${ORIG_MASTER_SSH_USER} \
--new_master_ssh_user=${NEW_MASTER_SSH_USER}
master_ip_online_change_scriptの実行が完了したら set global read_only = 0 が実行されて書き込みが行える状態となります。
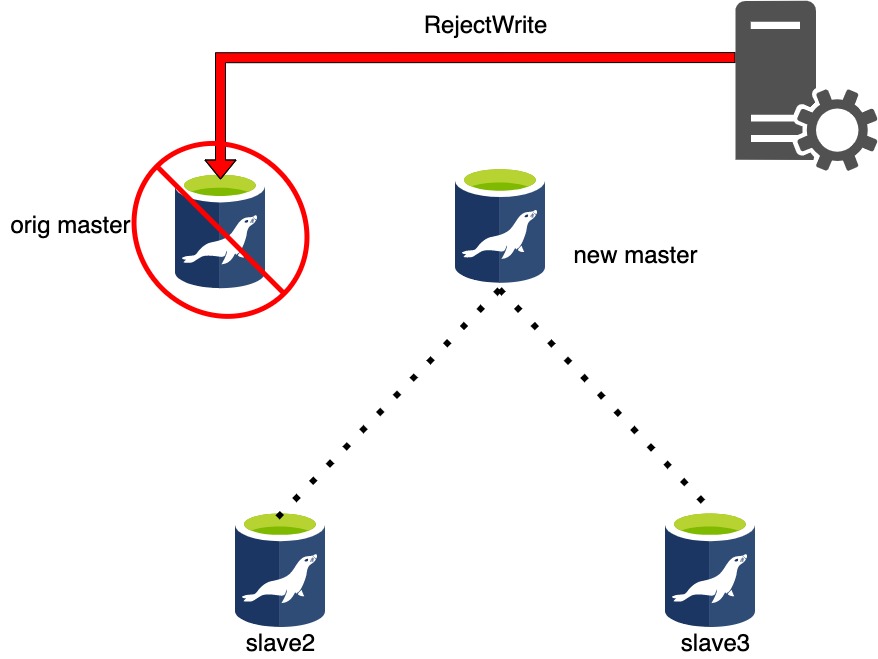
そして、マスタに昇格したスレーブにレプリケーションを張り直します。
Phase 5: New master cleanup phase..
Phase5はマスタに昇格したスレーブで reset slave all が実行されます。
Switching master to ${HOSTNAME}(${ADDRESS}:${PORT}) completed successfully. メッセージが表示されれば切り替え完了です。
最後に
MHAのフェイルオーバの動きは理解していただけたでしょうか。MHA実行時のトラブルに遭遇した時にお役いただけるとうれしいです。
MHAは非常によくできたHAツールですが、あくまでマスタ・スレーブの構成管理ができている前提で動作します。 ミラティブでは構成管理するためにマスタ・スレーブの構成監視やMHAのconfを動いているマスタ・スレーブ構成から生成していて、いつでもMHAが実行できる環境を整えています。
今回は紹介しきれなかったので、いずれまた紹介できたらなと思います。
We are hiring!
ミラティブでは サービスの拡大と安定化を支えるインフラエンジニアを募集中です! meetup も開催しているため気軽にご参加ください!