はじめに
はじめまして、Takata Harunariと申します。現在大学4年生で、分散システムを専攻しています。 2025年6月から12月までインフラチームでインターンとしてお世話になりました。
本記事では、内製オブジェクトストレージ「b3」が実運用を模した負荷に十分に耐えうることを確認するために実施した性能検証のプロセスについて紹介します。 具体的には、Go製ベンチマーカーの実装、そして検証過程で直面した技術的課題と解決策についても触れます。
b3とは
b3は、ミラティブが内製しているS3互換APIを持つオブジェクトストレージです。 詳細はこちらの記事をご覧ください。
ミラティブの配信サービスにおいては、サムネイル画像や録画データ、録画のアーカイブデータを保存する目的で開発されました。
背景と課題
b3オブジェクトストレージの再リリース
b3のバージョンアップ(v1.1 → v1.2)に伴い、クラスタ構成を含む大幅なアーキテクチャ変更が行われました。 この再リリースに向けて、改めて性能試験を実施する必要が生じました。
前回のリリース時の知見を活かしつつ、実運用を模した柔軟な混合負荷シナリオの精密な制御も実現することを目指しました。 その上で、新たな性能要件を満たすためにGo製のベンチマーカーを開発しました。
検証環境
本検証で使用したサーバー実機のストレージ構成は以下の通りです。
- データ用領域: 12TB SAS HDD (7.2Krpm) RAID6 構成
- RAIDキャッシュ設定: Write-through
IO性能の事前検証
ベンチマークに先立ち、b3が稼働するサーバー実機のディスクI/O性能を検証しました。
- レイテンシ: 各書き込みシステムコールの所要時間を記録し、統計分布(P50〜P99.5)を算出しました。
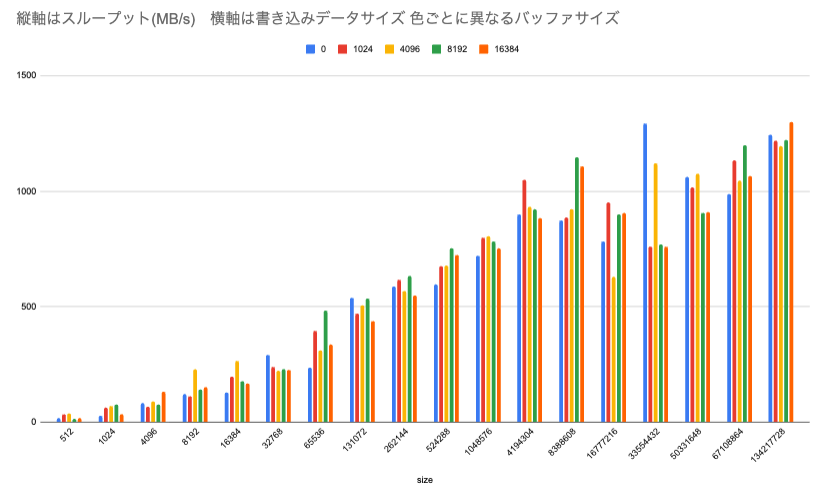
- スループット: 書き込みデータサイズを512バイトから128MBまで段階的に増加させながら、バッファサイズごとの転送速度の推移を計測しました。
その結果、書き込みサイズが4MBを超えたあたりでスループットは頭打ちになり、ピーク時で約1000MB/s前後のスループットとなることが確認できました。
検証の目的と予測
今回の検証では、2つの主要な試験を通じてb3の性能を評価しました。
第一に、ピーク性能試験では、b3のピーク性能を明らかにすることを目的としました。
指定した並列度で連続的にリクエストを送り、1リクエストあたりのレイテンシとシステム全体の平均スループットを計測しました。 この試験では、ネットワーク遅延の影響を極力排除した構成としました。
その上で並列数と書き込みオブジェクトサイズを増加させることで、スループットはディスクI/Oの上限である1000MB/sに達するまで向上し続けると予測しました。 また、もし上限に達しない場合でも、各種メトリクスを比較することでボトルネックとなっている箇所を特定できると考えていました。
第二に、UploadやDownload単体の性能ではなくさまざまな負荷傾向を模した秒間リクエスト数とオブジェクトサイズで試験し、レイテンシとスループットの推移を観測する試験(以下、混合試験)を実施しました。 この試験では、実運用を模した負荷と同等、あるいはそれ以上の負荷をかけた場合を想定しました。
そのような状況でもリクエストの滞留は発生せず、秒間リクエスト数に応じたスループットが安定して維持されると予測しました。 さらに、オブジェクトサイズ(5MB, 10MB)によって性能が異なり、最適なサイズが存在する可能性も探りました。
ベンチマーカーの設計と実装
本検証で用いたベンチマーカーは、Go言語を用いて独自に開発しました。
主な目的は、b3クラスタのS3互換APIエンドポイントであるapi-routerに対し、UploadおよびDownloadリクエストを発生させることです。
本ツールにより、レスポンスのレイテンシとシステム全体のスループットを精密に計測します。
システム構成
検証環境のシステム構成を以下に示します。
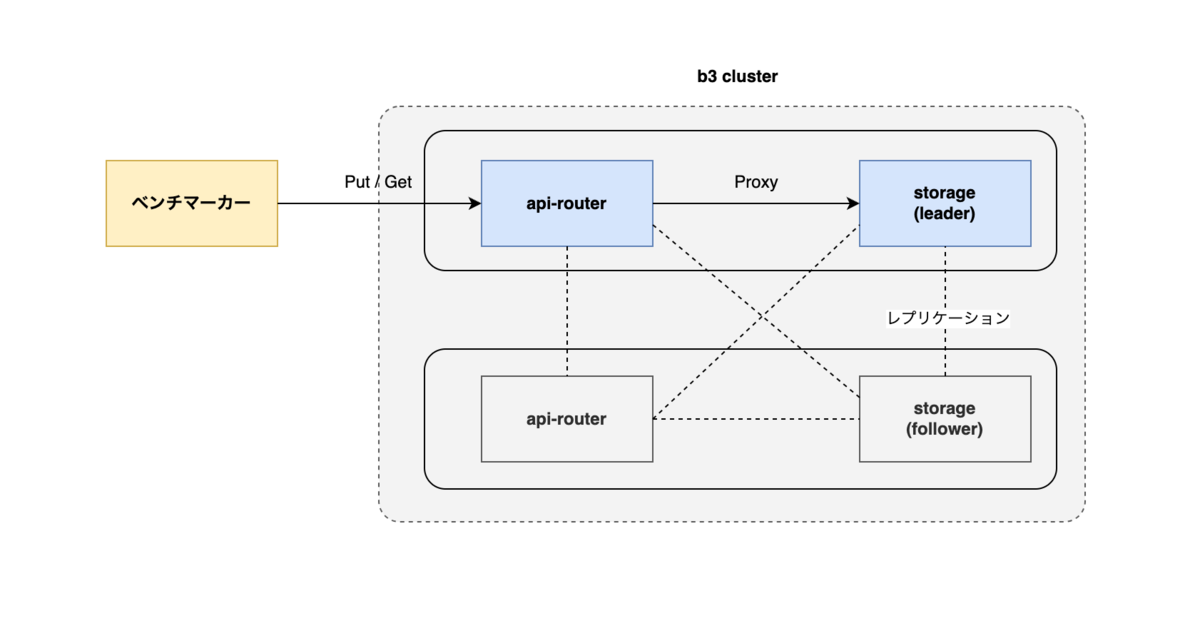
b3クラスタは、v1.2からリクエストの受付とstorageノードへの振り分けを行うapi-routerと、実際にオブジェクトを保存・取得する複数のstorageノードから構成されるようになりました。
api-routerはstorageノードへのプロキシとして機能し、受け取ったリクエストをleader権限を持つstorageノードへ転送します。
今回の検証では、ネットワーク遅延を最小化し、b3自体の性能を純粋に評価するため、ベンチマーカーをstorageのleaderノードと同一ホスト上に配置しました。
結果として、api-routerへのリクエストはローカルネットワーク通信(localhost経由)で行われます。
実装の詳細
ベンチマーカーの主な実装詳細は以下の通りです。
S3クライアント
b3はS3互換APIを提供しているため、AWS SDK for Go v2のs3managerパッケージを利用しました。
これにより、マルチパートアップロードやダウンロードの並列化といった複雑な処理を抽象化し、効率的なリクエスト生成を簡潔に実装できました。
並行処理モデル
多数のクライアントからの同時アクセスをシミュレートするため、ワーカープールモデルを採用しました。 ワーカーの生成と管理には、構造化された並行処理を実現できる sourcegraph/conc ライブラリを利用しました。 指定した並列数での安定したリクエストの生成と、各リクエストの実行結果の確実な集約をシンプルなコードで実現できました。
検証内容と結果
ピーク性能試験
ピーク性能試験では、b3のUpload/Downloadにおけるピーク性能、すなわちスループットとレイテンシが安定して処理できる上限の発見を目的としました。 試験は、並列数を1から128まで、オブジェクトサイズを1KBから10GBまで変化させて実施しました。
実装面では、sourcegraph/concのResultErrorPool.WithMaxGoRoutinesを用いることで、ワーカー数を指定した並列数以下に制限しています。
// 1. 並列処理プールの準備 p := pool.NewWithResults[time.Duration]().WithMaxGoroutines(goNum) // 2. 指定回数 (totalCount) だけタスクを非同期に投入 go func() { for i := 0; i < totalCount; i++ { p.Go(worker) } }() // 3. 全タスクの完了を待ち、結果を回収 results, err := p.Wait()
また、CPU、メモリ、ネットワーク帯域、ディスクI/O、IOPSを計測し、ボトルネックの有無を確認しました。
さらに、iostatを1秒間隔で実行し、ディスクI/Oの傾向を詳細に追跡しました。
Download の性能
Download 性能に関しては、試験の直前に対象となるキーのデータをすべてUploadしておきました。 これにより、Download時には常にキャッシュヒットが発生しないように考慮しました。

上記はDownload時のスループットのグラフ。横軸は、並列数順にグループ化したオブジェクトサイズを示します。縦軸はスループット(MB/s)です。条件によっては、スループットが1000MB/s近くまで到達していることがわかります。
Upload の性能
Upload 性能に関しては、すべてのオブジェクトがユニークになるようにUploadしました。 これにより、常にディスクに書き込みが発生するようにしました。

上記はUpload時のスループットのグラフ。横軸は、並列数順にグループ化したオブジェクトサイズを示します。縦軸はスループット(MB/s)です。いずれの条件でもスループットが1000MB/sまで到達しないことがわかります。
試験の結果
Download時の最大スループットは1000MB/s近くまで達しているのに対し、
Upload時の最大スループットは約750MB/sとなり、目標としていた1000MB/sには到達しませんでした。
この時のCPU使用率は10%未満であり、レプリケーションで使用するNICの帯域も逼迫してなかったため、CPUやネットワークが原因ではないことがわかりました。
当時のディスクI/O状況を iostat で確認すると、ディスク使用率(%util)は試験中ほぼ常に96%〜100%に張り付いていました。
また、書き込み待機時間(w_await)も数百msまで増大していました。
13:31:34 Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util ... 13:31:34 sdb 1.00 4.00 0.00 0.00 5.00 4.00 1230.00 1079540.00 31.00 2.46 198.88 877.67 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 244.63 100.00 13:31:35 avg-cpu: %user %nice %system %iowait %steal %idle 13:31:35 0.06 0.00 0.41 1.36 0.00 98.17 13:31:35 Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util ... 13:31:35 sdb 0.00 0.00 0.00 0.00 0.00 0.00 1280.00 1122692.00 36.00 2.74 211.74 877.10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 271.03 99.90 13:31:36 avg-cpu: %user %nice %system %iowait %steal %idle 13:31:36 0.05 0.00 0.34 1.41 0.00 98.20 13:31:36 Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util ... 13:31:36 sdb 1.00 4.00 0.00 0.00 81.00 4.00 1049.00 935272.00 38.00 3.50 176.45 891.58 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 185.18 98.00
Upload時のiostatのログを一部抜粋
混合試験
混合試験の目的は、性能そのものの計測ではなく、上限がどこにあるのかを特定することです。
これにより、どれくらいの秒間リクエスト数(req/s)が発生するとリクエストが滞留し始めるかを確認します。
また、安定したスループットが維持されるかも検証します。
試験項目として、基準負荷(ベースライン)、クラスタの片肺運転時の負荷(高負荷)、さらにベースラインよりも秒間リクエスト数を2〜8倍に高めた状態での試験をそれぞれ60秒間行いました。 またMirrativ特有の傾向として、録画データは録画設定が有効な配信であれば常に保存されます。
一方で録画データは録画を見に行くユーザ数に比例するため、Downloadの秒間リクエスト数はUploadよりも小さくなっています。
基準負荷(ベースライン)
Downloadは約9MB/s、Uploadは約118MB/sの負荷が発生する状態を基準としました。
オブジェクトサイズが5MBの場合、Downloadは2 req/s、Uploadは24 req/s に相当します。
オブジェクトサイズが10MBの場合、Downloadは1 req/s、Uploadは12 req/s に相当します。
クラスタの片肺運転時の負荷(高負荷)
障害発生による縮退運転(一部のノードが停止し、残りのノードに負荷が集中する状況)を想定し、通常時よりも高い負荷がかかるシナリオを想定しています。
ノード数の減少に伴う負荷の偏りが発生するため、ベースラインの約1.2倍〜1.3倍程度の負荷が発生するものとしました。
具体的には、Downloadは約12MB/s、 Uploadは約147MB/sの負荷が発生。
オブジェクトサイズが5MBの場合、Downloadは 3 req/s、Uploadは 30 req/s に相当します。
オブジェクトサイズが10MBの場合、Downloadは 2 req/s、Uploadは 15 req/s に相当します。
この試験では、算出したreq/sに基づき、rate.Limiterを用いてワーカーの生成頻度を制御することで、指定したワークロードを再現しました。
// 1. 並列処理プールの準備 p := pool.NewWithResults[workerStat]() limiter := rate.NewLimiter(rate.Limit(reqPerSec), burst) // req/s に基づくリミッター for { select { case <-ctx.Done(): // 2. 全タスクの完了を待って結果を回収 results := p.Wait() // 3. データの整理(フィルタリングとソート) finalResults = filter(results) // 有効な結果のみ sort(finalResults) return finalResults default: // 4. リミッターで流量制限しつつ、非同期でタスクを投入 limiter.Wait(ctx) p.Go(worker) } }
混合試験の結果

混合試験のグラフ。横軸は秒間のリクエスト数をもとにした負荷のパターン、縦軸はスループット(MB/s)を示します。
一定の秒間リクエスト数を超えるとスループットが頭打ちになることがわかりました。
負荷を上げていくことでスループットが頭打ちになるだけでなく、むしろ減少する現象も確認できました。
ベースライン・高負荷においては、リクエストが滞留することなく安定して処理できることが確認でき、どれくらいの負荷までクラスタを構成できるか、クラスタ全体の構成数なども基準負荷を元に検討できるようになりました。
考察とトラブルシューティング
性能に関する考察
b3 は Bitcask アーキテクチャを採用しており、データはシーケンシャルに追記されます。
しかし、高並列なリクエストが集中する環境下では、単一の内部DBへのアクセスに起因するロック競合や、OS・ファイルシステムレベルでの排他制御がオーバーヘッドとなり、ディスクの持つ性能を完全には引き出しきれていない可能性があります。 負荷試験の結果からスループットは理論値に届きませんでした。
今後の改善策として、アプリケーション側で内部DBの水平分散数を調整し、ロックの粒度をさらに細かくすることで競合を低減させれば、より効率的にディスクの性能を使い切ることができ、実測値をハードウェアの理論値(約1000MB/s)にさらに近づけられると予測しています。
ただし約750MB/sという数値自体は、低すぎるわけではなく基準負荷の数倍までは性能を維持できることから十分な性能と言えます。
Downloadのスループットは、最も高い場合でハードウェア限界に近い数値に達し、ディスクのI/O性能を十分に引き出せていることが確認できました。
混合試験では、実運用を模した負荷と同等の負荷、および高負荷時(障害想定)においては、リクエストが滞留することなく安定して処理できることを確認しました。 また、実運用を模した負荷の最大6倍までの秒間リクエスト数であれば、スループットを維持できることが分かりました。 一方で、6倍を超える負荷においてスループットが減少してしまった詳細な原因については、より深く調査する余地が残っています。
検証中に発生した問題と対応
性能検証の過程で、いくつかの技術的課題を発見・修正しました。
最初に問題となったのは、ポート枯渇です。
api-router と storage 間の内部で利用する httputil.ReverseProxy の MaxIdleConnsPerHostがデフォルトで2に制限されていました。
そのため、コネクションが再利用されず TIME_WAIT 状態のコネクションが急増し、試験中にポート枯渇となる問題がありました。
対策として、api-router のアイドル接続数を適切な値に設定し、コネクションを再利用することで問題を解消しています。
他には、負荷試験中に並列数を増加させたときやオブジェクトサイズを大きくした時にはb3独自のオンメモリキャッシュ機構がメモリを大量に消費する問題が顕在化しました。
そのため、それまでは固定で行っていたキャッシュのeviction(追い出し)ポリシーを調整可能にする修正を行いました。
次に、マルチパートアップロード時のリソース消費問題が判明し、修正しました。
b3ではマルチパートでアップロードされたデータをダウンロードする際に、一時的にディスクへ展開してからメモリに読み込む実装となっていました。
これが原因で、ダウンロード時にディスクとメモリを過剰に消費していました。
この問題に対しては、直接ダウンロード時にデータをストリームとしてクライアントに返すように実装を変更し、リソースの消費を大幅に削減できました。
さらに、並列数を増加させた際に競合問題も発生したため、修正を行いました。
これは、ベンチマーカーによって並列数を増加させた際に一部のリクエストでレスポンスが正常に返却されませんでした。
調査の結果、共有リソースへのアクセス箇所がスレッドセーフになっていない箇所を特定し、排他制御を実装し正常に返却できるようにしました。
以上のような問題をチームで対応しつつ性能検証を進めました。
まとめと今後の展望
今回の検証を通じて、Go製のベンチマーカーを開発し、b3がハードウェアの性能を十分に引き出していることを性能面から確認できました。
Downloadでは条件によってディスクI/O性能の限界に近い性能を引き出せる、UploadではディスクI/O性能の約75%程度までしか出せていないという結果が得られました。
また、今回の試験では行えませんでしたが、より長期的な安定性を評価するための耐久試験の実施が必要だと考えています。
特に、b3が採用しているログ構造化ツリーであるBitcaskのバックグラウンド処理であるマージ(コンパクション)処理を繰り返し長期間行うテストは必要不可欠です。
インターンシップで得た学び
エンジニアとしての成長
- 尊敬すべき仲間とロールモデルとの出会い:
- 技術力はもちろん、エンジニアとしての「在り方」を体現する方々に囲まれ、自身の目標となるロールモデルに数多く出会えました。ミラティブで働く上では、ただコードを書くだけでなく、多くの議論を積み重ねて業務が進行します。むしろコードを書く時間よりも議論している時間の方が多いと感じるほどで、「エンジニア=コードを書く仕事」だと思っていた私にとっては、非常に意外な発見でした。
- オープンなコミュニケーション文化:
- チームは非常にオープンで、いつでも相談できる心理的安全性の高い環境でした。特に、技術選定において全員が納得するまで議論を尽くす文化は、非常に印象的でした。私の作成したベンチマーカーも、インフラストリーミングチームの皆様と議論を重ねながら開発をすすめることができました。
- オブジェクトストレージ開発の奥深さ:
- b3を構成する多様なコンポーネント(I/Oを占有しないためのバックグランド削除, 細やかなI/O制限, レプリケーション, リーダー選出など)が、試行錯誤の末に洗練されてきた過程を学びました。b3ではユーザーエクスペリエンス向上のため、数十ms単位での改善が繰り返されています。ハードウェアに最適化した実装や、ミラティブのトラフィック特性に合わせたチューニングも徹底されており、その技術的なこだわりの深さに圧倒されました。
学んだこと
- 計測に基づく論理的アプローチの重要性:
- 「推測するな、計測せよ」という原則に基づき、実測値を起点に論理的な計算を経て仮説検証する開発プロセスを学びました。当初の私は、数値計算やI/Oの仕組みを検討する際、実験する前から推測だけで結論を出そうとしてしまうことがありました。しかし、これはインフラストリーミングチームの「推測するな、計測せよ」という原則に反する振る舞いです。まずは正確に計測をし、その数値を元に論理を組み立てる。このプロセスを徹底することの重要性を、身をもって実感しました。
- スピード感のある開発:
- インターン当初、私は実装前に仕様や手法を考えすぎるあまり、なかなか手を動かせず、十分なアウトプットを出せずにいました。そんな時、上長から頂いたのが「完璧よりまず動くものを (Done is better than perfect)」という言葉です。 細部にこだわりすぎて進捗を止めるのではなく、まずは動くものを素早く作り上げ、そこから「計測と改善」のサイクルを回していく。このスピード感と実践的なアプローチの重要性を、深く学ぶことができました。
- 「風が吹いたら桶屋が儲かるメソッド」
- 社内で共有するドキュメントを作成する際、論理的な文章構成に苦戦し、伝えたいことを的確に表現できず悩んでいました。その時、上長から教わったのが「風が吹いたら桶屋が儲かるメソッド」です。 結論を端的に述べること、そしてその裏側に「結論まで一本道で繋がるロジック」を丁寧に忍ばせること。そうすることで、いかなる深掘りに対しても自信を持って説明できるようになります。つまり、物事を端的に伝える力と、深い説明力の双方を鍛えるという教えです。これを意識して文章を書くようにしてから、自分でも手応えを感じるほど、論理の通った「納得感のある文章」が書けるようになりました。
- Goによる実践的な開発経験:
- メンターの指導のもと、ベンチマーカー開発などの実務に取り組み、Goの文法やベストプラクティスを深く習得しました。コメントの記述、変数の命名、エラーハンドリングなど、これまで自分が軽視しがちだった基礎こそが、チームでコードを育てる上では極めて重要であることを痛感しました。 また、自律的な学習としてElectionアルゴリズムの実装などにも挑戦。その結果、最終的にはb3の競合状態(Race Condition)といった高度な問題も、自力で特定できるまでになりました。さらに、b3の開発に欠かせないのが、並行プログラミングです。並行プログラミングには、当初苦手意識がありました。しかし、上長の手厚い指導と継続的なコードリーディングを通じて、徐々にその勘所を掴むことができました。 具体的には、
sourcegraph/concを用いた構造化された並行処理の実践や、デバッグを通じた排他制御の重要性の理解など、理論と実践の両面から深く学ぶことができました。
- メンターの指導のもと、ベンチマーカー開発などの実務に取り組み、Goの文法やベストプラクティスを深く習得しました。コメントの記述、変数の命名、エラーハンドリングなど、これまで自分が軽視しがちだった基礎こそが、チームでコードを育てる上では極めて重要であることを痛感しました。 また、自律的な学習としてElectionアルゴリズムの実装などにも挑戦。その結果、最終的にはb3の競合状態(Race Condition)といった高度な問題も、自力で特定できるまでになりました。さらに、b3の開発に欠かせないのが、並行プログラミングです。並行プログラミングには、当初苦手意識がありました。しかし、上長の手厚い指導と継続的なコードリーディングを通じて、徐々にその勘所を掴むことができました。 具体的には、
We are hiring!
ミラティブのインフラでは日々成長しているミラティブを観測して、サービスの品質をより良くしていくためにインフラを設計してミドルウェアを選定したり、または運用ツールや監視を内製したりしています。 サービスの手触りを感じつつ日々成長するサービスを支えるための技術や知識を学んでみたいという方おまちしております!