こんにちは ハタ です。
今回は以前iOSのクライアントサイドで実装していた通知ぼかし機能をサーバサイド(配信サーバ)上に再実装した事を書きたいなと思います
今回はかなり内容を絞りに絞ったのですが、長くなってしまいました、、
目次機能があったのでつけてみました、読み飛ばして読みやすくなった(?)かもしれません
目次
通知ぼかし機能とは
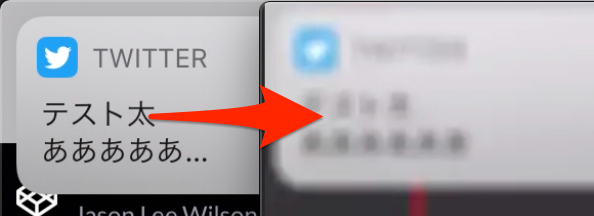
通知ぼかし機能は、ミラティブ上での配信中に写り込んでしまったiOSの通知ダイアログをダイアログの中身を見えないようにぼかし処理をしてあげる機能のことです

以前はクライアント端末側で実装していた通知ぼかし機能ですが、下記のような問題点がありました
- 配信中に通知ダイアログの検出およびぼかし処理を行うため端末が熱くなる
- 配信の異常終了率が上がる
どちらも端末側での処理が大きくなっていることが原因で、既存の配信処理(収録 + エンコーディング + 配信)に加えて通知ぼかし処理を行うのは難しく快適な配信を行えなくなってしまうことから機能そのものがなくなっていました
ですが、TwitterやLINEなどの通知が配信に写り込んでしまうことを防ぐために、今回クライアントサイドではなく、サーバサイドで通知ぼかしを再実装することにしました
サーバサイド通知ぼかし
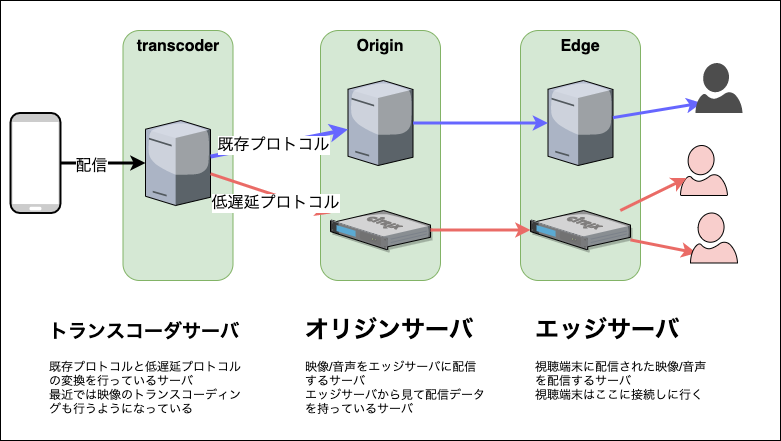
ミラティブの配信サーバは上記のような構成となっていて、トランスコーダサーバというものが前段に立っていて、映像/音声を受け取るようになっています
今回のサーバサイド通知ぼかしはこのトランスコーダサーバ上に実装しました
以前はiOS上で動作するためにSwiftで実装されていたので、それをGoで再実装ようにしました
基本的な方針は以前のものと同じですがいくつか違いがある状態で実装しています
(以前の実装内容は 過去の記事をご覧ください)
- 【同じ】教師データなしのアルゴリズムで実装する
- 【違い】ダークモードにも対応するため輝度変化による検出ロジックを変えている
- 【違い】端末の情報が取れないため画像回転処理などは別に用意している
- 【同じ】ミラティブの通知はぼかし処理を行わない(アイコンの検出)
配信サーバ上では多数の配信を受けていることから、かなり処理速度にはシビアに実装する必要がありました
例えば30fpsの配信を受けている場合に、1配信あたり30fps程度のトランスコーディングの速度(約30ms)だとして、複数の配信すべてを30msで処理していてはトランスコーダサーバあたりの収容率が下がってしまい、膨大な数のサーバが必要になってしまいます
その他にも、ミラティブではスケーラビリティの観点からできる限り汎用的なサーバを選択するようにしているため、極力CPU処理だけで処理速度を出せるように注意して実装する必要がありました
そのためクライアントサイドで実装するものよりもう少し工夫したアルゴリズムを組んだりする必要がありました
今回はこうした事情から、ちょっとだけ頑張った最適化処理や利用したライブラリについて書いていきたいなと思います
プロトタイプの実装
既存のSwiftのロジックがあるため、プロトタイプはGoだけを使って実装することにしました
GoのImageパッケージ では画像処理によく利用する YCbCr や画像解析処理で処理しやすい RGBA が利用できるため比較的簡単に実装できそうでした
苦労の始まり その1 画像処理速度

これはiOSの通知ダイアログが出てくるアニメーションなのですが、最初の文字が見えるまでの時間を見るとおおよそ3フレーム前後には最初の文字が見えてくることがわかりました
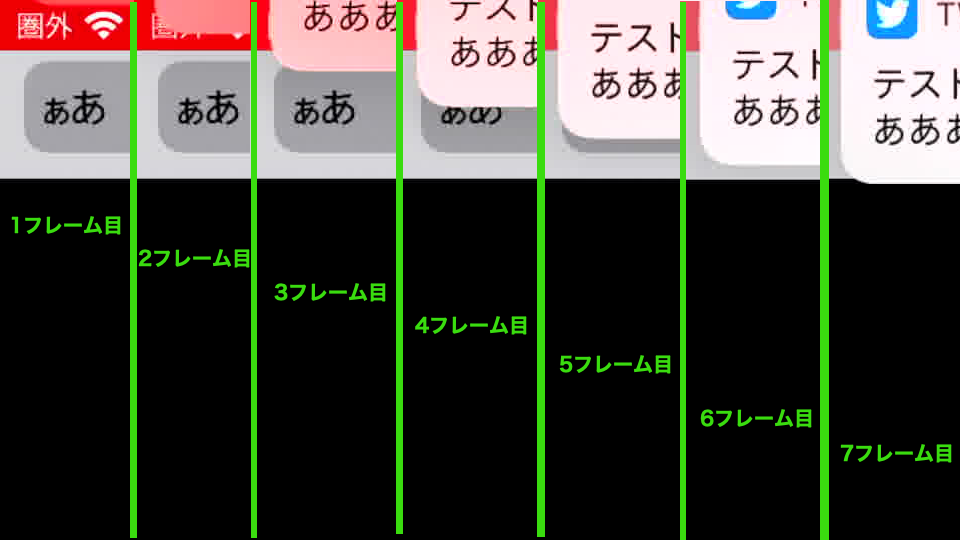
通知ぼかしでは通知内容を見えないようにしたいため、3フレーム目(おおよそ 100ms以下)で通知ダイアログの判定とぼかし処理を行う必要があります
当初愚直にそのままアルゴリズムのSwiftからGoに移植すればよいのだろうと進めていたのですが
愚直にそのままだとあまりにも実行時間が伸びるものがいくつか出てきました
例えば以下のような YCbCr <-> RGBA に変換する処理です
import ( "image" "image/color" "image/draw" ) func rgbaToYCbCr420(src *image.RGBA) *image.YCbCr { r := src.Bounds() dst := image.NewYCbCr(r, image.YCbCrSubsampleRatio420) for y := 0; y < r.Dy(); y += 1 { for x := 0; x < r.Dx(); x += 1 { rgba := src.RGBAAt(x, y) yy, uu, vv := color.RGBToYCbCr(rgba.R, rgba.G, rgba.B) cy := dst.YOffset(x, y) ci := dst.COffset(x, y) dst.Y[cy] = yy dst.Cb[ci] = uu dst.Cr[ci] = vv } } return dst } func ycbcrToRGBADraw(src *image.YCbCr) *image.RGBA { r := src.Bounds() dst := image.NewRGBA(r) draw.Draw(dst, dst.Bounds(), src, image.Pt(0, 0), draw.Src) return dst }
これだけを見ると image/color や image/draw を使うことで非常にシンプルに変換できるため使いたかったのですが
大量の映像フレームを扱うことになってくるとこのあたりの処理速度が気になってきます
下記は 360p の1フレームあたりの処理時間です、RGBA -> YCbCr に 3.914ms / YCbCr -> RGBA に 0.976ms 合わせて 4.89ms ほどかかりそうです
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkRGBAToYCbCr420 BenchmarkRGBAToYCbCr420-8 304 3914520 ns/op BenchmarkYCbCrToRGBADraw BenchmarkYCbCrToRGBADraw-8 1214 976054 ns/op PASS
RGBA -> YCbCr のコード(rgbaToYCbCr420) は X,Y で2重のループになっているのですが、 RGBA を扱う1次元配列の中身は [R, G, B, A, R, G, B, A] のように 4 bound で1つ、また Stride 毎に決められているため
X * Y 回数だけループを回るよりも多少 unroll が行えそうです
下記のように書き直してみました
func rgbaToYCbCr420Unroll(src *image.RGBA) *image.YCbCr { b := src.Bounds() width, height := b.Dx(), b.Dy() stride := 4 // 4 = r + g + b + a dst := image.NewYCbCr(b, image.YCbCrSubsampleRatio420) for i := 0; i < height * width * stride; i += stride { r := src.Pix[i + 0] g := src.Pix[i + 1] b := src.Pix[i + 2] _ = src.Pix[i + 3] // A yy, uu, vv := color.RGBToYCbCr(r, g, b) is := i / stride h := is / width w := is % width cy := (h * dst.YStride) + w ci := ((h / 2) * dst.CStride) + (w / 2) dst.Y[cy] = yy dst.Cb[ci] = uu dst.Cr[ci] = vv } return dst }
結果として、多少改善しましたが(3.9ms から 3.4ms)ほんのわずかでした
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkRGBAToYCbCr420 BenchmarkRGBAToYCbCr420-8 300 3928816 ns/op BenchmarkRGBAToYCbCr420Unroll BenchmarkRGBAToYCbCr420Unroll-8 349 3409538 ns/op PASS
RGBA -> YCbCr は仕方がないとして、 YCbCr -> RGBA はどうでしょうか
今回扱っている YCbCr のサブサンプリングは 4:2:0 のため、いわゆる YUV420 なのである程度 stride 毎に unroll 効果が期待できたりするかもしれません
func ycbcrToRGBA(src *image.YCbCr) *image.RGBA { b := src.Bounds() width, height := b.Dx(), b.Dy() rgbPlane := make([]byte, width * height * 4) // 4 = r + g + b + a i := 0 for h := 0; h < height; h += 1 { for w := 0; w < width; w += 1 { y := src.Y[(h * src.YStride) + w] u := src.Cb[((h / 2) * src.CStride) + (w / 2)] v := src.Cr[((h / 2) * src.CStride) + (w / 2)] r, g, b := rgbBT2020Limited(y, u, v) rgbPlane[i + 0] = r rgbPlane[i + 1] = g rgbPlane[i + 2] = b rgbPlane[i + 3] = 0xff // A i += 4 } } return &image.RGBA{Pix: rgbPlane, Stride: 4 * width, Rect: b} } func rgbBT2020Limited(y, u, v byte) (r, g, b byte) { yf, uf, vf := float64(y), float64(u), float64(v) yy := (yf - 16.0) * 1.164384 uu := (uf - 128.0) vv := (vf - 128.0) rr := yy + (1.67867 * vv) gg := yy - (0.187326 * uu) - (0.65042 * vv) bb := yy + (2.14177 * uu) r = byte(clamp(rr, 0.0, 255.0)) g = byte(clamp(gg, 0.0, 255.0)) b = byte(clamp(bb, 0.0, 255.0)) return } func clamp(value float64, min, max float64) float64 { if value < min { return min } if max < value { return max } return value }
結果的にこれも早くなったりしませんでした(BenchmarkYCbCrToRGBADrawが元のDrawを使った処理)
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkYCbCrToRGBADraw BenchmarkYCbCrToRGBADraw-8 1258 951475 ns/op BenchmarkYCbCrToRGBA BenchmarkYCbCrToRGBA-8 606 1942185 ns/op PASS
ただ、これらはforループで逐次処理してるためですが、もう少しCPU命令を使えれば最適化できそうです
libyuv はこうした処理に最適化されているためそれぞれ次のように実装しました
import( "fmt" "image" ) /* #cgo CFLAGS: -I${SRCDIR}/include #cgo LDFLAGS: -L${SRCDIR} -lyuv #include "libyuv.h" */ import "C" func libyuvRGBAToI420(src *image.RGBA) (*image.YCbCr, error) { r := src.Bounds() w, h := r.Dx(), r.Dy() y := make([]byte, w * h) u := make([]byte, ((w + 1) / 2) * ((h + 1) / 2)) v := make([]byte, ((w + 1) / 2) * ((h + 1) / 2)) ret := C.ABGRToI420( (*C.uchar)(&src.Pix[0]), C.int(w * 4), (*C.uchar)(&y[0]), C.int(w), (*C.uchar)(&u[0]), C.int(w / 2), (*C.uchar)(&v[0]), C.int(w / 2), C.int(w), C.int(h), ) if int(ret) != 0 { return nil, fmt.Errorf("error desu i420") } return &image.YCbCr{ Y: y, Cb: u, Cr: v, YStride: w, CStride: w / 2, Rect: image.Rect(0, 0, w, h), SubsampleRatio: image.YCbCrSubsampleRatio420, }, nil } func libyuvI420ToRGBA(src *image.YCbCr) (*image.RGBA, error) { r := src.Bounds() w, h := r.Dx(), r.Dy() rgba := make([]byte, w * h * 4) ret := C.I420ToABGR( (*C.uchar)(&src.Y[0]), C.int(src.YStride), (*C.uchar)(&src.Cb[0]), C.int(src.CStride), (*C.uchar)(&src.Cr[0]), C.int(src.CStride), (*C.uchar)(&rgba[0]), C.int(w * 4), C.int(w), C.int(h), ) if int(ret) != 0 { return nil, fmt.Errorf("error desu rgba") } return &image.RGBA{ Pix: rgba, Stride: w * 4, Rect: image.Rect(0, 0, w, h), }, nil }
CGOの呼び出しの場合で最初にハマるのは、 byte slice を unsignec char* に変換する処理でしょうか、スライスの先頭のアドレスを渡してあげるのですが、久しく C/C++ を触っていなかったので少し戸惑いました
また (*C.uchar)(&slice[0]) よりももう少しちゃんと書くとすると (*C.uchar)(unsafe.Pointer(&slice[0])) 等になるかもしれません、ここではいったん割愛します
上記コードで image.RGBA は [R, G, B, A] のカラーモデルですが、 ABGRToI420 や I420ToABGR として [A, B, G, R] と逆順のカラーモデルとして呼び出してます
これは FORCC マクロにしたがっているためで LittleEndian の世界から見るとややこしいのですが、いったんこれについても割愛します(今回とは別軸でハマりポイントがあるのでいつか書きたいと思ってます)
さて、 libyuv にしたことにより RGBA -> YCbCr が 0.075ms (Go版は 3.914ms) / YCbCr -> RGBA が 0.125ms (Go版は 0.976ms) となりかなり処理速度が向上しました
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkLibyuvRGBAToI420 BenchmarkLibyuvRGBAToI420-8 15346 75770 ns/op BenchmarkLibyuvI420ToRGBA BenchmarkLibyuvI420ToRGBA-8 8844 125419 ns/op PASS
libyuv を使用することにより、画像の回転処理も最適化された呼び出しが行えるので、これを利用するようにしていきました
苦労の始まり その2 データ量

以前の実装では輝度変化に着目して特徴量を計算するようにしていました
これはこれでも良いのですが大量のフレームの走査領域のデータを極力減らしたいと考えました
例えば次のような画像の変化量がある領域とそれ以外の領域に分割してみると骨組みだけ取り出すことができます
ロジックとしては下記のようにしてみました
func maxDeriavVar(img *image.RGBA, x, y int, count int) float64 { rSum := float64(0) gSum := float64(0) bSum := float64(0) rgbF := func(c color.RGBA) (float64, float64, float64) { return float64(c.R), float64(c.G), float64(c.B) } ptF := func(x, y int) (float64, float64) { return float64(x), float64(y) } prevR,prevG,prevB := rgbF(img.RGBAAt(x, y)) prevPtX,prevPtY := ptF(x, y) for i := 1; i < count; i += 1 { ptX, ptY := ptF(x + i, y + i) d := math.Max(ptX - prevPtX, ptY - prevPtY) r,g,b := rgbF(img.RGBAAt(x + i, y + i)) rd := math.Abs(r - prevR) / d gd := math.Abs(g - prevG) / d bd := math.Abs(b - prevB) / d rSum += rd * rd gSum += gd * gd bSum += bd * bd prevR,prevG,prevB = r, g, b prevPtX,prevPtY = ptX, ptY } return math.Max(rSum, math.Max(gSum, bSum)) } func draw(img *image.RGBA) *image.RGBA { c := 8 b := img.Bounds() width, height := b.Dx(), b.Dy() mono := image.NewRGBA(b) for y := 0; y < height - c; y += 1 { for x := 0; x < width - c; x += 1 { if 50000 < maxDeriavVar(img, x, y, c) { mono.SetRGBA(x, y, color.RGBA{0, 0, 0, 255}) } else { mono.SetRGBA(x, y, color.RGBA{255, 255, 255, 255}) } } } return mono }
if 50000 < var としている 50000 はただのしきい値なのであまり意味は無いのですが、次のような画像が出力されるようになりました

ここまで出来れば、 0 と 1 に置き換えることができそうです
uint64 では 8byteで64bit長 のビットを扱うことができるため、2値化の結果を保存するようにします
func imgbits(img *image.RGBA) [][]uint64 { c := 8 b := img.Bounds() width, height := b.Dx(), b.Dy() val := make([][]uint64, height - c) for y := 0; y < height - c; y += 1 { wc := (width - c) / 64 val[y] = make([]uint64, wc) for x := 0; x < wc; x += 1 { b := uint64(0) for i := 0; i < 64; i += 1 { if 50000 < maxDeriavVar(img, (x * 64) + i, y, c) { b |= 1 << (64 - i) } } val[y][x] = b } } return val }
この結果を fmt.Printf("%064b", val[y][x]) すると 0 と 1 で構成されたデータを作り出すことができました

さて、ここで 0 と 1 のデータが作れたことで、 popcount がしやすくなりました
popcount は bit列の中から 1 が付いている個数を個数を取り出す関数です
go では math/bitsにOnesCount64 として実装されています
popcount が利用できることで、ハミング距離の計算も行いやすくなります
例えば何かしらのテンプレートとなる bit列を用意しておき、 XOR で差分を取り差分が小さいものほどテンプレートに一致しているということが取れます
go-popcount では AMD64 系に最適化された popcount を使用でき、また、まとめて uint64 slice の popcount を求めてくれるので、それを利用します
import ( "fmt" "github.com/tmthrgd/go-popcount" ) func main() { tpl := []uint64{ 0b_0000_0000_0000_0000, 0b_0000_0111_1111_0000, 0b_0000_0100_0001_0000, 0b_0000_0100_0001_0000, 0b_0000_0111_1111_0000, 0b_0000_0000_0000_0000, } Foo := []uint64{ 0b_0000_0000_0000_0000, 0b_0000_0100_0001_0000, 0b_0000_0100_0001_0000, 0b_0000_0100_0001_0000, 0b_0000_0100_0001_0000, 0b_0000_0000_0000_0000, } Bar := []uint64{ 0b_0000_0000_0000_0000, 0b_0000_0111_1111_0000, 0b_0000_0000_0000_0000, 0b_0000_0111_1111_0000, 0b_0000_0111_1111_0000, 0b_0000_0000_0000_0000, } hammingDistance := func(a, b []uint64) uint64 { d := make([]uint64, cap(a)) for i := 0; i < cap(a); i += 1 { d[i] = a[i] ^ b[i] } return popcount.CountSlice64(d) } fmt.Println(hammingDistance(tpl, Foo)) // => 10 fmt.Println(hammingDistance(tpl, Bar)) // => 7 fmt.Println(hammingDistance(tpl, tpl)) // => 0 }
今回は直接紹介しないのですが bit列を扱えることで ビットシフトを行うことで 画像を必要サイズだけ移動させることができるのも便利な点です
func main() { val := []uint64{ 0b_0000_0000_0000_0000, 0b_0000_0111_1111_0000, 0b_0000_0100_0001_0000, 0b_0000_0100_0001_0000, 0b_0000_0111_1111_0000, 0b_0000_0000_0000_0000, } right := func(v []uint64, size int) []uint64 { c := make([]uint64, cap(v)) for i := 0; i < cap(v); i += 1 { c[i] = v[i] >> size } return c } fmt.Println("origin") for _, v := range val { fmt.Printf("%016b\n", v) } fmt.Println("right 2") for _, v := range right(val, 2) { fmt.Printf("%016b\n", v) } } // => origin // => 0000000000000000 // => 0000011111110000 // => 0000010000010000 // => 0000010000010000 // => 0000011111110000 // => 0000000000000000 // => right 2 // => 0000000000000000 // => 0000000111111100 // => 0000000100000100 // => 0000000100000100 // => 0000000111111100 // => 0000000000000000
さらなる計算量の削減を求めて
2値化とpopcountを使用することで アクティブ探索法も行いやすくなりました
情報量が少ない領域は popcount = 0 とみなすことができるため、情報がある領域だけ計算を行うようにできます

例えば上記のような画像では、人間の目にはダイアログの範囲が分かりますが、機械の目で見た時にできるだけそれっぽい領域で計算を行ってもらうように、特徴量が少ない領域を読み飛ばす必要があります

上記の動画は、2値化とpopcountを組み合わせた処理後にプログラムが走査している領域をトレースしたものです
情報がほとんどない領域は読み飛ばしていることがわかると思います
あとはさらに物体を検出できる領域だけに絞り込むことで計算量が減らせます
この処理を組み合わせることでミラティブのアイコンがありそうな位置だけ計算するようにしてみたものがこちらになります

必要の無さそうな範囲は処理されていないことが見えると思います
さらなる最適化へ
ここまで古典的な、教科書的な最適化を行いある程度使用に耐えれる速度になりました
ここでは紹介できていませんでしたが、他にもいくつか手をつけていきました
- ブラー処理を Goで実装されたガウスぼかし から libyuvのARGBBlur に変えたり
- 画像の回転処理を bild/Rotate から libyuvのARGBRotate に変えたり
- スケールおよびクリップ処理を golang.org/x/image/draw から libyuvのARGBScaleClip に変えたり
など libyuv には便利なメソッドがたくさんあるため置き換えを行ったりしてます
Goで必要な画像解析処理を書き、速度が求められる場面では Cgo を経由して libyuv に処理させることである程度処理速度も確保できてきました
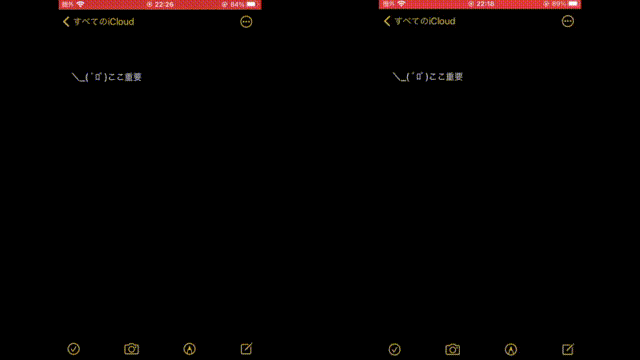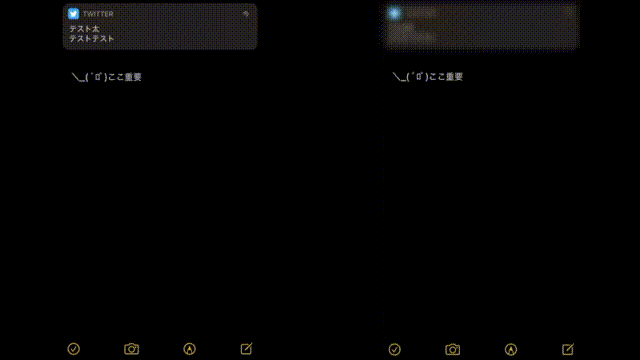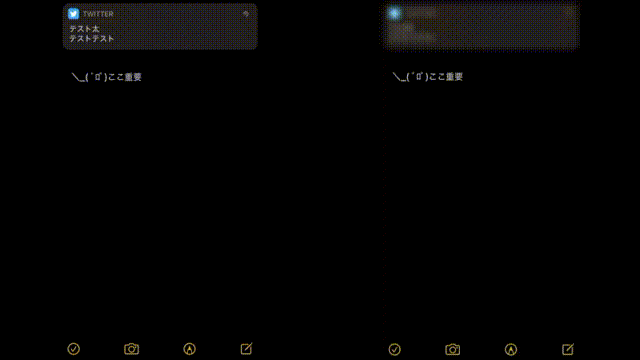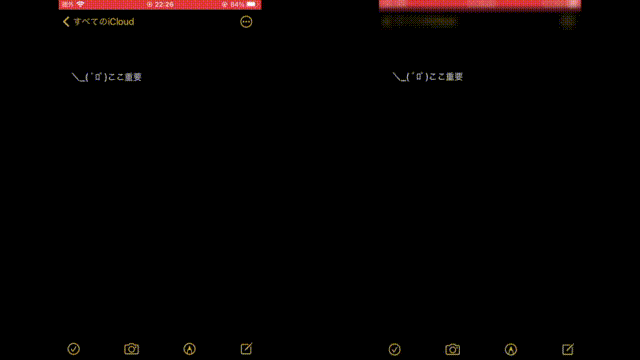
上記の動画は一通りの終わった後の通知ぼかしが行われる端末の画面の様子を録画してみたものを並べてみました
ここまでで、 Pure Go だけで実装していた場合だと(正確なログが残っていないのでざっくりになりますが)10-15fps程度(100ms+)だったものが 30fps(30ms以下)程度にはなりました
まだまだ遅いのでさらにチューニングを行っていきます
最初に手掛けたのはSIMDで処理できるところを置き換えていくことでした
例えば []byte 同士の AND 処理は、ほぼそのまま grailbio/base/simd に置き換えれます(AND以外もあります)
func BytesAnd(dst []byte, a, b []byte) {
- for i := 0; i < cap(a); i += 1 {
- dst[i] = a[i] & b[i]
- }
+ simd.And(dst, a, b)
}
これは、 処理内容にもよりますが大量の byte slice を処理する場合に効果があります
下記の /32, /64, /128 は要素数です、数が大きくなればなるほど差がでてきます
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkGo BenchmarkGo/32 BenchmarkGo/32-8 140462671 8.460 ns/op BenchmarkGo/64 BenchmarkGo/64-8 76551399 16.49 ns/op BenchmarkGo/128 BenchmarkGo/128-8 16259034 74.08 ns/op BenchmarkSIMD BenchmarkSIMD/32 BenchmarkSIMD/32-8 223948428 5.355 ns/op BenchmarkSIMD/64 BenchmarkSIMD/64-8 170726116 7.042 ns/op BenchmarkSIMD/128 BenchmarkSIMD/128-8 100000000 11.04 ns/op PASS
他にも float64 の SUM も stuartcarnie/go-simd で置き換えたりが可能でした (いろんなパッケージ使っちゃってますね..)
さて、ここまで libyuv だったり SIMD 対応などを通して、実ロジック以外 cgo 経由の実行が増えてきました
大量の映像フレームを扱っているため、 cgo 経由のオーバヘッドも気になってきました
例えば、下記のような単純な四則演算の呼び出しですが
/* int add(int a, int b) { return a + b; } int sub(int a, int b) { return a - b; } int mul(int a, int b) { return a * b; } int foo(int a, int b, int c, int d) { int r1 = add(a, b); int r2 = sub(r1, c); int r3 = mul(r2, d); return r3; } */ import "C" func Add(a, b int) int { return int(C.add(C.int(a), C.int(b))) } func Sub(a, b int) int { return int(C.sub(C.int(a), C.int(b))) } func Mul(a, b int) int { return int(C.mul(C.int(a), C.int(b))) } func Foo(a,b,c,d int) int { r1 := Add(a, b) r2 := Sub(r1, c) r3 := Mul(r2, d) return r3 } func CFoo(a,b,c,d int) int { return int(C.foo(C.int(a), C.int(b), C.int(c), C.int(d))) }
これを cgo で呼び出した場合と、Cで直接呼び出した場合の benchmark です
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkFoo BenchmarkFoo-8 7721295 167.2 ns/op BenchmarkCFoo BenchmarkCFoo-8 23486498 49.88 ns/op PASS
この Foo(cgoから四則演算したもの) と CFoo(cgoを1回だけ経由したもの) の差分が、 cgo の FFI によるオーバヘッドだと考えられます
ちょうどいいスライド があったため、解説はこちらをみてもらうとして、やはりここも改善したいなと思うようになりました
(余談ですが、四則演算レベルであれば Go で実装したほうがはるかに早いです)
func goAdd(a, b int) int { return a + b } func goSub(a, b int) int { return a - b } func goMul(a, b int) int { return a * b } func GoFoo(a,b,c,d int) int { r1 := goAdd(a, b) r2 := goSub(r1, c) r3 := goMul(r2, d) return r3 } // goos: darwin // goarch: amd64 // cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz // BenchmarkGoFoo // BenchmarkGoFoo-8 1000000000 0.2443 ns/op // PASS
さて、SIMD処理への置き換えやその他ロジックの最適化等を行った結果、 300fps(3ms+) くらいまで下げることができました
cgoのオーバヘッドもそうなのですが、マイクロチューニングを頑張ろうと思えば頑張れるのですが、それよりもコードの見通しの悪さが目立つようになりました
極力 Go で書けるところは Go で書いていたのですが、ロジック(アルゴリズム)の修正とデータの持ち方の修正をどちらも行わなければならなく、このあたりからだんだん辛くなってきました
Halide の世界へ
前置きがかなり長くなってしまいましたが、今回メインで紹介したいのが halide-lang です
halide は C++ の DSL言語として利用できる、プログラミング言語です
大きな特徴はアルゴリズムとスケジューリングの分離が行える言語であることと、CPU/GPUなどに最適化されたコードを出力してくれる点が独特です
言語としてみたときの癖のようなものは強いのですが、それよりもコード全体の見通しの良さや強力な最適化(スケジューリングのチューニングが行いやすい)はメリットとして上回るものがあります
簡単な halide の紹介
halide の紹介は こちらのスライド がとてもまとまっているので、割愛しますが
Goで書いた時の画像処理と halide で書いた画像処理の違いを紹介したいなと思います
例として、グレースケールをGoで書いた時のコードです
const( GRAY_R int = 76 GRAY_G int = 152 GRAY_B int = 28 ) func Grayscale(src *image.RGBA) *image.RGBA { b := src.Bounds() w, h := b.Dx(), b.Dy() dst := image.NewRGBA(b) for y := 0; y < h; y += 1 { for x := 0; x < w; x += 1 { c := src.RGBAAt(x, y) gray := ((GRAY_R * int(c.R)) + (GRAY_G * int(c.G)) + (GRAY_B * int(c.B))) grayB := byte(gray) dst.SetRGBA(x, y, color.RGBA{ R: grayB, G: grayB, B: grayB, A: 0xff, }) } } return dst }
このときの benchmark 結果です、シンプルな処理なのでさほど気になる処理速度ではありません(0.54ms)
goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-8569U CPU @ 2.80GHz BenchmarkGrayscale BenchmarkGrayscale-8 2215 540880 ns/op PASS
これを halide に置き換えてみます、halideでは For の中身を関数にして記述するイメージで画像処理を書くことができます
const int16_t GRAY_R = 76, GRAY_G = 152, GRAY_B = 28; Func grayscale(Buffer<uint8_t> in) { Var x("x"), y("y"), ch("ch"); Func f = Func("grayscale"); Expr r = cast<int16_t>(in(x, y, 0)); Expr g = cast<int16_t>(in(x, y, 1)); Expr b = cast<int16_t>(in(x, y, 2)); Expr gray = ((r * GRAY_R) + (g * GRAY_G) + (b * GRAY_B)) >> 8; Expr value = select( ch == 0, gray, // R ch == 1, gray, // G ch == 2, gray, // B 255 // A ); f(x, y, ch) = cast<uint8_t>(value); return f; }
これの実行ですが、 halide は AOT の他に JIT でも実行できるため、今回は JIT で実行します
int main(int argc, char **argv) { Buffer<uint8_t> src = load_and_convert_image(argv[2]); Func fn = grayscale(src); fn.compile_jit(get_jit_target_from_environment()); Buffer<uint8_t> out = fn.realize({src.get()->width(), src.get()->height(), 4}); // 4 => r + g + b + a save_image(out, argv[3]); return 0; }
また、benchmarkですが、 halide tools の benchmark を使うことで計測できます
int main(int argc, char **argv) { Buffer<uint8_t> src = load_and_convert_image(argv[2]); Func fn = grayscale(src); fn.compile_jit(get_jit_target_from_environment()); double result = benchmark(1000, 100, [&]() { fn.realize({src.get()->width(), src.get()->height(), 4}); }); printf("%s: %-3.5fms\n", fn.name().c_str(), result * 1e3); return 0; }
さて、この結果から次のように出力され、0.01570ms とまぁまぁそこそこの結果です
grayscale: 0.01570ms
halideの本領を発揮するのはここからです
すでに作成済みの関数に手を加えず次のように schedule を追加します
やっていることは、ch 単位に parallel、 x方向にベクトル処理をするようにしました
Func grayscale(Buffer<uint8_t> in) {
Var x("x"), y("y"), ch("ch");
Func f = Func("grayscale");
...
f(x, y, ch) = cast<uint8_t>(value);
+ // schedule
+ f.compute_root()
+ .parallel(ch)
+ .vectorize(x, 16);
return f;
}
このときの結果は 0.00895ms とほぼコードを書き換えずにチューニングすることができました
grayscale: 0.00895ms
今回はグレースケール処理のため、シンプルなのですが他にもチューニングすることができそうです
例えば unroll 処理を加えてみたり、tile化などもできるかもしれません
// unroll f.compute_root() .unroll(ch, 4) .parallel(y) .vectorize(x, 16); // tile f.compute_root() .tile(x, y, xo, yo, xi, yi, 16, 16) .fuse(xo, yo, ti) .parallel(ch) .parallel(ti, 4) .vectorize(xi, 16);
より詳細はイメージ画像とともにこちらの動画で紹介されているのでご覧ください
halide によって既存ロジックを置き換えることなく、スケジューリングによってチューニングができるようになったのはとても大きく、また チューニングを加えることがなくてもそこそこの良い速度で処理できるのも良いです
その後、 libyuv や SIMD などの処理をすべて halide に置き換えを行いました
いままでカオスだったロジックがシンプルになり、halide に置き換えができたのは正解だったかもしれません

上の動画はその当時に撮影したもので、大きく遜色なくダイアログの検出とぼかし処理が行われていると思います
この時点で、0.7ms 程度でfpsにすると1400fpsくらいでしょうか、(もろもろ荒削りですが)検出からぼかし処理までを行えるようになっていました
1ms以下にできたのはとても大きいです
苦労の始まり その3 いざ リリース
いざリリースを行って最初に遭遇したのは SEGV 関連のサーバクラッシュです
Go 単体でのデバッグは比較的容易なのですが、 cgo が絡むととても難易度があがります
クラッシュで一番多かったのは、 malloc などで確保した領域外のアクセスでした
例えば次のようなコードです
/* #include <stdlib.h> typedef struct { int x; int y; unsigned char *buf; } my_result_t; my_result_t *exec(int x, int y) { my_result_t *r = (my_result_t *) malloc(sizeof(my_result_t)); if(r == NULL) { return NULL; } r->x = x; r->y = y; return r; } */ import "C" func Exec(x, y int) *C.my_result_t { r := C.exec( C.int(x), C.int(y), ) return r } func foo() { r := Exec(12345, 5678) println(r.buf) // ここで signal SIGSEGV: segmentation violation ... }
おそらく上記コードでは落ちることはないので、SEGVになるイメージのコードなのですが、Goに慣れていると ゼロ値で初期化されているつもりでコードを書いている箇所がクラッシュしがちでした
直すとしたらこんな感じでしょうか
my_result_t *exec(int x, int y) {
my_result_t *r = (my_result_t *) malloc(sizeof(my_result_t));
if(r == NULL) {
return NULL;
}
+ memset(r, 0, sizeof(my_result_t));
r->x = x;
r->y = y;
return r;
}
その他にも Cgo から C の関数を呼び出している場合に、stacktraceが表示されず途方に暮れることがあったのですが、cgosymbolizer は import するだけで利用できるので使うと便利でした
// #include ... // .... import "C" import ( _ "github.com/benesch/cgosymbolizer" )
他にも byte slice を cgo に渡す場合、逆に cgo 側で alloc した領域を Go で使う場合も結構こまめにケアが必要でした
いくつかケアするポイントがあった気がするので別途また書ければなと思っています
地道に穴埋めを頑張り、やっと安定するようになりました
即座にクラッシュするものばかりではなかったので、安定するまで本当に長い道のりでした
リリースその後
現在安定版がリリースされ数ヶ月がたちました
一部のiOSユーザさんはこの通知ぼかし機能が自動で適用さているようになっています
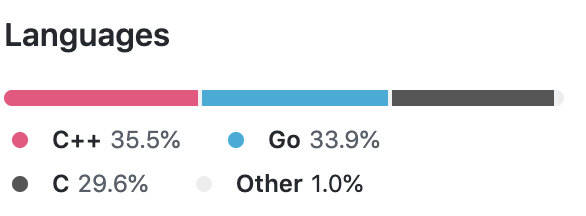
最終的にトランスコーダサーバのリポジトリは Go で書いたコードよりも C/C++ のコードのほうが多くなってしまいました
今回紹介しきれなかったのですが、画面の回転処理について紹介しきれていません
ミラティブの配信はスマートフォンが多くをしめるのため、ゲーム開始しているときの画面とエモモが表示されているときの画面で、結構頻繁にorientation(landscape/portrait)がちょくちょく変わります
今現在は、画面の3方向(-90/0/90)に対して通知ダイアログの検出を行うようにしているのですが、このあたりの情報はもう少しインタラクティブに端末とサーバで情報の交換(画面の回転情報)をできるようにできればなと思っています(絶賛実装中です)
他にもダークモード/ライトモードで輝度変化の違いがあるため、画像解析まわりで工夫したポイントは紹介しきれていません
機械学習などで精度を高めるためにやっていることとほぼ同じなのですが、なかなか面白かったのでいつか紹介したいなと思っています
今回登場した halide-lang ですが、よく使いそうな処理等とベンチマークを octu0/blurry にてまとめてみたライブラリを作ってみたので、気になる方は見ていただけるといいかもしれません
We are hiring!
クライアントサイドでできなかった事をサーバサイドで実現するために一緒に開発してくれるエンジニアを募集中です!
もっと最適化の余地がありそうなので我こそはと思った方、応募お待ちしております