こんにちは、バックエンド基盤チームマネージャーの夏(なつ)と申します。ミラティブの基盤チームはユーザが直接触れる機能よりかは、開発者や会社全体の生産性を向上させるためにエンジニア主導で課題を発見・解決している部署です。
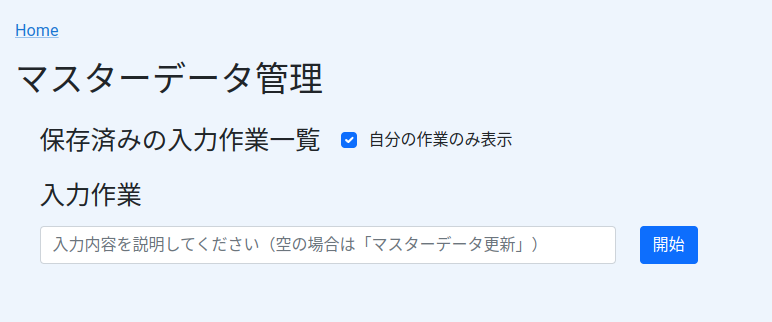
今回は基盤チームが主体となって運用しているマスターデータ管理システムについて紹介したいと思います。ゲーム運営などではエクセルやスプレッドシートで管理されることがよくありますが、学習コストや安全性の観点で入力者を増やしづらい場合があります。このような問題に対応するため、ミラティブでは一部のマスターデータをGitHub APIを利用した専用の管理画面を実装することで入力作業をスケールできるようにしました。
(なお、本記事は社内向けドキュメントを兼ねています)
マスターデータとは
マスターデータとはユーザによって生成されるデータではなく、主に運営が用意するデータになります。詳細としては、以下の特徴を持つデータのことを指します。
- 可搬性が高い
- お知らせやキャンペーンなどの情報
- 開発環境で検証したデータをそのまま本番環境に反映できる
- キャンペーンについてもタイトルや開催期間などの情報が対象で、達成状況などユーザとの中間テーブルなどの情報は含まない
- アトミック性が求められる
- 編集中の不完全な状態がユーザの目に触れてはいけない
- ソースコードと同等レベルでの管理が望ましい
- 変更差分が分かりやすい
- 変更履歴をトラッキングしやすい
- 不具合発生時に切り戻しやすい
- エンジニア以外によって更新可能
- ソースコードのデプロイとは分離されている
- マスターデータのデプロイ頻度は基本的にソースコードよりも多い
ミラティブはSNS的な要素が強いサービスということもあり、リリース当初は基本的にユーザによって生成されるデータぐらいしかありませんでした。そのため当初は運営が生成するデータに関しても必要に応じて開発環境の管理画面上で入力・検証した上で、本番環境の管理画面に人力でコピーして反映することで運用していました。
その後、エモモというアバター機能が登場し、また様々なキャンペーンやランキングなどのイベントを行うようになってくると、運営が生成するデータが爆発するようになりました。データ量や複雑性が増してくると検証完了したデータを人力で本番へコピーしていては事故リスクが上がってきます。ゲーム運営などではスプレッドシートでデータを入力、CSVへエクスポート、開発環境で動作確認完了したらGitで本番反映するのが一般的かと思いますが、例に漏れずミラティブでも一部のマスターデータはこの方式を採用しています。
スプレッドシートによる入力の課題
少人数で入力している間は上記の方法が適していましたが、よりたくさんのマスターデータを入力しようとすると運用上の問題も発生するようになってきました。とくにミラティブでは常にたくさんのゲームが配信されており、各ゲームごとにキャンペーンなどを実施しようとすると入力者が増えても安全に運用できる体制が求められます。スプレッドシートはRDBのテーブル構造という実装詳細がそのまま露出しているおかげで、一覧性が高かったり、専用の管理画面を実装しなくても済みます。また強力な関数やマクロにより利用者自身で各種自動化が可能な点も魅力的です。
一方で利用者がテーブルの実装詳細を多少理解する必要があったり、エンジニアによるテーブル構造のリファクタリングの影響を直接受けたりします。また画像などのテキスト以外のバイナリデータの管理方法が自明ではなく、入力者に画像ファイルだけ直接Git操作を要求する場合があるなど、学習コストが高く入力操作を覚えるのに時間がかかるという問題もありました。
そこでマスターデータとしてのアトミック性や可搬性を維持した上で、実装詳細を適切に抽象化したバックエンドや従来の管理画面のような専用の入力システムを実装することで、入力者がスケールした場合でも安全性や運用コストを担保できるようにしました。本記事ではこのようなシステムをGitHub APIによって実装したことについて紹介したいと思います。
内部実装
基本的にはエンジニアが普段行うGit操作をマスターデータ用に特化させて、ブラウザ上から行えるようにしたフローとなっています。
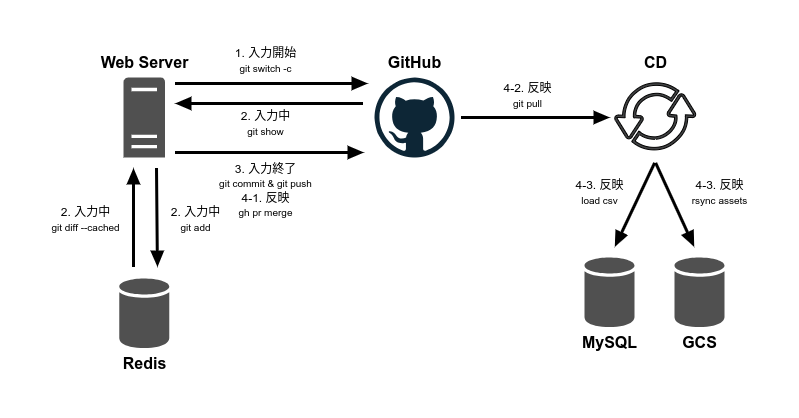
以下の解説では実際に利用しているGitHub APIと、理解促進のため対応するコマンドを併記しています。
1. 入力開始
デフォルトブランチから新しいブランチを作成。
# git switch -c {branch_name}
POST /repos/{owner}/{repo}/git/refs {
"ref": "refs/heads/{branch_name}",
"sha": "{base_branch_sha}"
}
2. 入力中
更新や削除時は該当のレコードをgocsv でCSVにencodeして、 内製のRedisサーバ に保存。
# git add {master_data_csv_path}
# 実際はRedisに保存
画像などのバイナリファイルは都度GitHubにアップロード。
# git commit -m "[skip ci] add master_data assets" && git push
POST /repos/{owner}/{repo}/git/blobs {
"content": "{base64_encoded_image}",
"encoding": "base64"
}
POST /repos/{owner}/{repo}/git/trees {
"base_tree": "{branch_tree_sha}",
"tree": [{
"path": "{master_data_image_path}",
"mode": "100644",
"type": "blob",
"sha": "blob_sha"
}]
}
POST /repos/{owner}/{repo}/git/commits {
"message": "[skip ci] add master_data assets",
"tree": "{tree_sha}",
"parents": ["{branch_commit_sha}"]
}
PATCH /repos/{owner}/{repo}/git/refs/refs/heads/{branch_name} {
"sha": "{commit_sha}"
}
# gh pr create
POST /repos/{owner}/{repo}/pulls {
"title": "{title}",
"head": "{branch_name}",
"base": "{base_branch_name}"
}
(初期ではテキストデータも都度GitHub APIでCSVをアップロードしていたが、データ量が多いテーブルのCSVではアップロードに時間がかかるため、入力作業終了時にまとめてgoroutineで並列アップロードするよう修正)
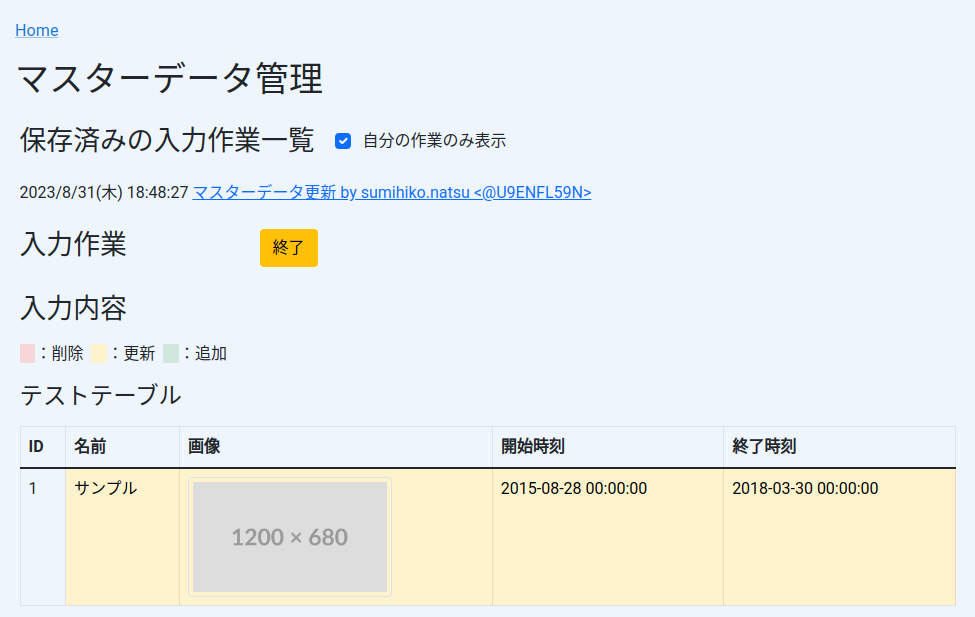
マスターデータ表示時は作成したブランチ内のCSVをGitHubから取得し、そこに更新や削除が入ったレコードのCSV情報をRedisから取得し、主キーを用いてマージ。
# git show origin/{branch_name}:{master_data_csv_path}
GET /repos/{owner}/{repo}/git/commits/{branch}
GET /repos/{owner}/{repo}/git/trees/{tree_sha}
GET /repos/{owner}/{repo}/git/blobs/{blob_sha}
# git diff --cached {master_data_csv_path}
# 実際はRedisから取得
画像ファイルは /assets/git_blob_{commit_sha}_{master_data_image_path} というURLで生成しておいて、該当のパスのリクエストに対してはGitHub APIで実体を取得するような http.FileSystem を実装し http.FileServer を噛ませてルーティングさせている。
これらの処理はDataSourceレイヤーのMasterDataによって共通化し、以下のようなインターフェイスとして公開されているのでそれぞれのRepositoryはこれらの関数を呼ぶだけでよい。
type MasterData interface { SelectAll(ctx context.Context, operator *entity.Operator, tableName string, out any) error UpdateRows(ctx context.Context, operator *entity.Operator, tableName string, isDelete bool, rows any) error UploadAssets(ctx context.Context, operator *entity.Operator, assets map[string][]byte) error }
(SelectAllは入力中でない場合はMySQLからレコードを取得するので、これにより本番環境に反映済みのデータも同一の画面で確認可能)
入力の差分は以下のような画面で確認可能
3. 入力終了
入力開始時のCSVに対してUpdateRowsにより差分が発生したレコードのCSVを主キーを元に上書きしたCSVを作成してGitHubへアップロード
# git commit -m "[skip ci] update master_data csv" && git push # 画像ファイルアップロードと重複するので省略
4. 反映
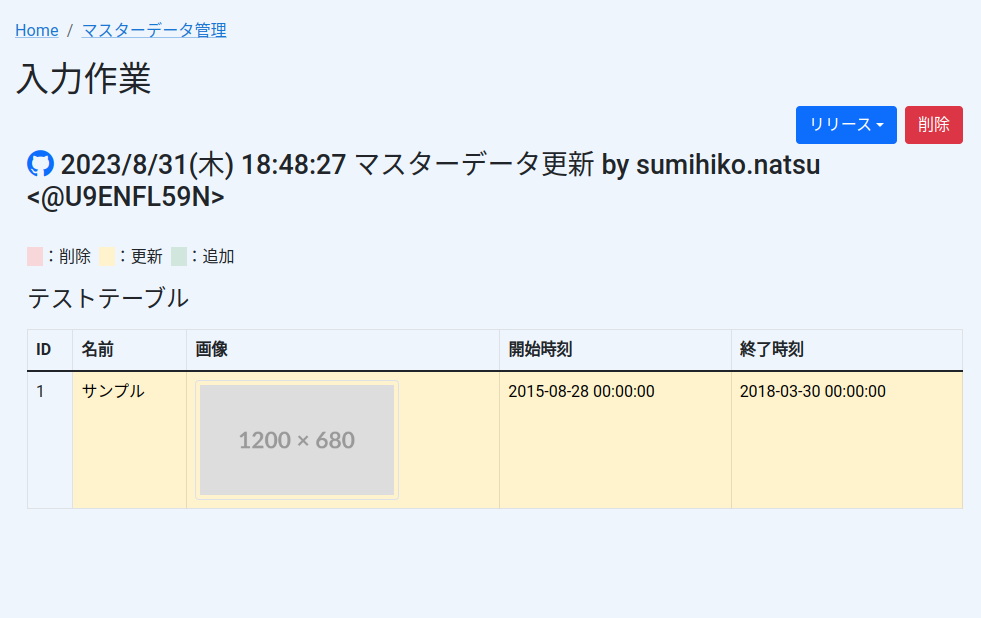
基本的にはプルリクエストをマージするだけ。
# gh pr merge {pr_number}
PUT /repos/{owner}/{repo}/pulls/{pr_number}/merge
開発環境宛に反映したい場合、プルリクエストから一時的なブランチを作成し、対象の環境に該当するブランチに対してマージする。
複数人が同時に新規データを追加した場合、CSVの最後に追記されていくため大抵の場合コンフリクトしてしまうのだが、マスターデータの性質上 主キーによって別々のデータが新規追加されていることを判断できるためコンフリクトを自動解消できる。 (逆に主キーが同一のレコードを更新しようとしていた場合には自動的に修正できないため、コンフリクトとして表示する)
プルリクエストがマージされると本番環境のContinuous Deliveryシステム(社内ではauto-deployくんと呼ばれる)によりgit pullが行われ、CSVであればMySQLにロード、画像ファイルなどであればGoogle Cloud Storageに同期されCDNで配布される。
おわりに
一世代前のマスターデータの入力システムでは普通のデータと同じく直接MySQLに更新を行い、入力作業終了時にmysqldump相当の処理を行い、そのCSVをGitHubにpushしていました。しかし、それでは一つの環境で一度に一人しか入力できなかったりと弊害が出たため、思い切ってMySQLにINSERT/UPDATEするところを全部GitHubにしてみようと思ったのがきっかけです。これにより入力作業中はデータの永続先がMySQLではなくGitHubの各ブランチになり、お互いの入力作業が衝突せず複数人が同時に入力作業できるようになりました。
一方で当たり前ですが、専用の入力画面を作る分エンジニアの開発工数はかかります。またスプレッドシートと違い利用者による自動化が難しいので、そのあたりをいつか管理画面へのローコードツールの導入などで埋められると便利かなと思いました。
We are hiring!
ミラティブではユーザへ価値提供するために部署を横断して全体最適を目指せるエンジニアを絶賛募集中です!!